「データサイエンス 数学ストラテジスト 上級」はデータサイエンスの基盤である、確率・統計、線形代数、微積分、機械学習、プログラミングなどを取り扱う資格試験です。当記事では「日本数学検定協会」作成の「公式問題集」の演習問題$11$〜$20$の解答例を取り扱いました。
・数学検定まとめ
https://www.hello-statisticians.com/math_certificate
演習問題
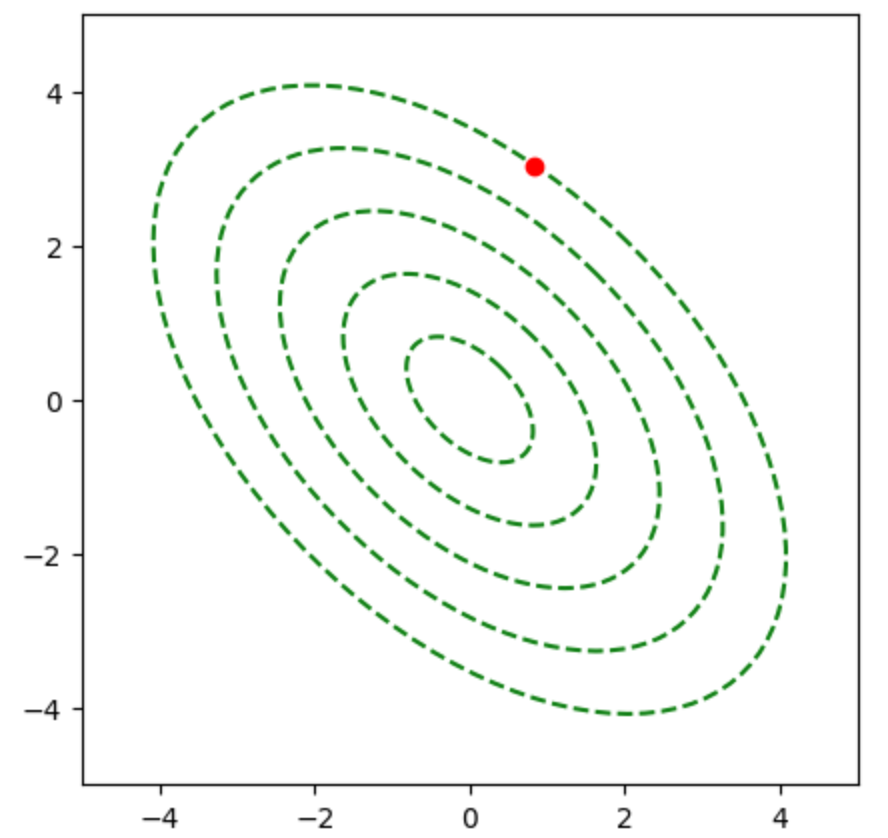
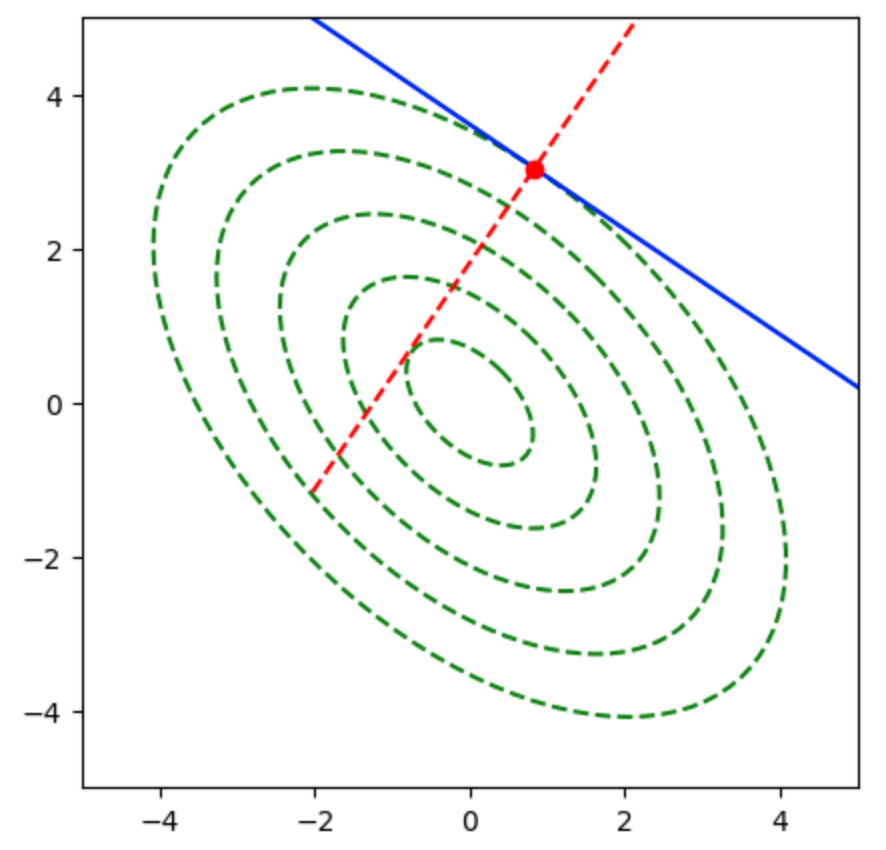
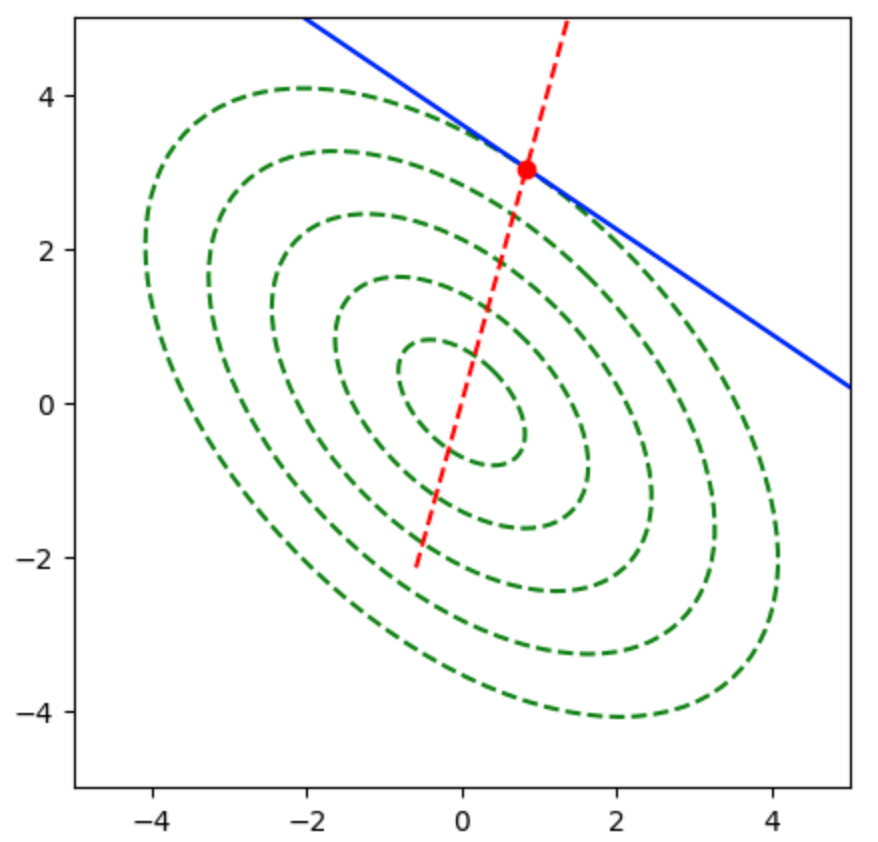
Q.11
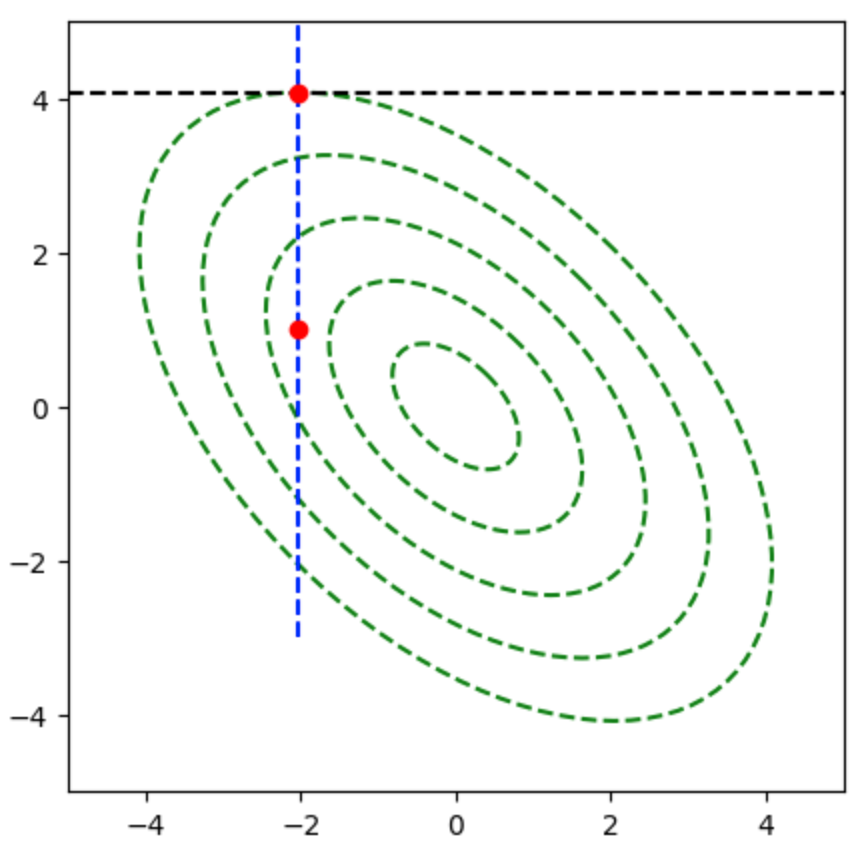
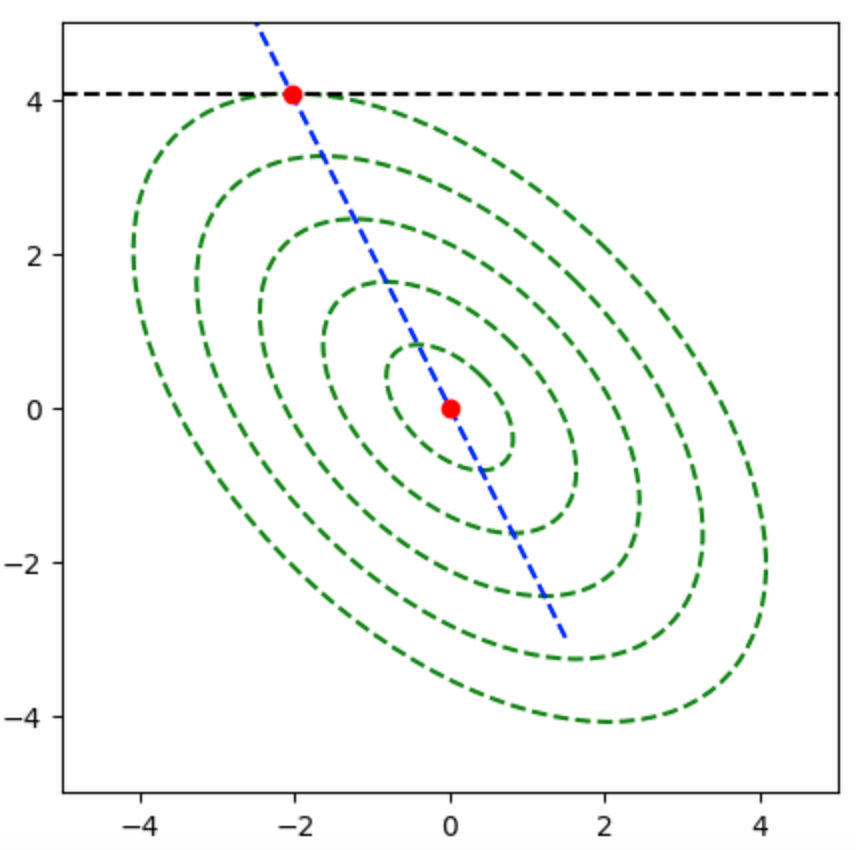
$\overrightarrow{AB}$と$\overrightarrow{OH}$はそれぞれ下記のように表すことができる。
$$
\large
\begin{align}
\overrightarrow{AB} &= \overrightarrow{OB} – \overrightarrow{OA} \\
\overrightarrow{OH} &= t \overrightarrow{OA} + (1-t) \overrightarrow{OB}
\end{align}
$$
ここで$\overrightarrow{AB} \perp \overrightarrow{OH}$であるので、$\overrightarrow{AB} \cdot \overrightarrow{OH} = 0$が成立するが、下記のように変形できる。
$$
\large
\begin{align}
\overrightarrow{AB} \cdot \overrightarrow{OH} &= 0 \\
(\overrightarrow{OB} – \overrightarrow{OA}) \cdot (t \overrightarrow{OA} + (1-t) \overrightarrow{OB}) &= 0 \\
t &= \frac{70}{127}
\end{align}
$$
よって、$\overrightarrow{OH}$は下記のように表すことができる。
$$
\large
\begin{align}
\overrightarrow{OH} = \frac{70}{127} \vec{a} + \frac{57}{127} \vec{b}
\end{align}
$$
上記より$(4)$が正しい。
Q.12
下記のように式変形を行える。
$$
\large
\begin{align}
\lim_{n \to \infty} \left[ \log_{10}{(n+100)} – \log_{10}{(1000n+1)} \right] &= \lim_{n \to \infty} \log_{10}{\frac{n+100}{1000n+1}} \\
&= \lim_{n \to \infty} \log_{10}{\frac{1+100/n}{1000+1/n}} \\
&= \log_{10}{\frac{1}{1000}} \\
&= \log_{10}{10^{-3}} \\
&= -3
\end{align}
$$
上記より$(5)$が正しい。
Q.13
$$
\large
\begin{align}
y = \frac{6}{(e^{x}+1)(e^{x}+3)}
\end{align}
$$
$e^{x}>0$より、$0 \leq x \leq 1$で$y>0$である。よって、図形の面積を$S$とおくと、$S$は下記のように立式できる。
$$
\large
\begin{align}
S = \int_{0}^{1} \frac{6}{(e^{x}+1)(e^{x}+3)} dx \quad [1]
\end{align}
$$
上記に対し、$t=e^{x}$のような変数変換を行う。このとき$\displaystyle \frac{dt}{dx}=e^{x}$より、$\displaystyle \frac{dt}{t}=dx$が成立する。また、$x$と$t$の区間は下記のように対応する。
| $x$ | $0 \longrightarrow 1$ |
| $t$ | $1 \longrightarrow e$ |
よって$[1]$式は下記のように値を得ることができる。
$$
\large
\begin{align}
S &= \int_{0}^{1} \frac{6}{(e^{x}+1)(e^{x}+3)} dx \quad [1] \\
&= \int_{1}^{e} \frac{6}{t(t+1)(t+3)} dt \\
&= \int_{1}^{e} \left[ \frac{2}{t} – \frac{3}{t+1} + \frac{1}{t+3} \right] dt \\
&= \left[ 2\log{|t|} – 3\log{|t+1|} + \log{|t+3|} \right]_{1}^{e} \\
&= \left( 2\log{e} – 3\log{(e+1)} + \log{(e+3)} \right) – \left( 2\log{1} – 3\log{(1+1)} + \log{(1+3)} \right) \\
&= 2 – 3\log{(e+1)} + \log{(e+3)} + \log{2}
\end{align}
$$
上記より$(3)$が正しい。
・解説
途中計算では下記のような部分分数分解を行いました。
$$
\large
\begin{align}
\frac{6}{t(t+1)(t+3)} = \frac{2}{t} – \frac{3}{t+1} + \frac{1}{t+3}
\end{align}
$$
上記の分解を発見するにあたっては、$\displaystyle \frac{6}{t(t+1)(t+3)} = \frac{a}{t} + \frac{b}{t+1} + \frac{c}{t+3}$とおき、両辺が一致するように$a, b, c$の値を得れば良いです。
$$
\large
\begin{align}
\frac{a}{t} + \frac{b}{t+1} + \frac{c}{t+3} &= \frac{a(t+1)(t+2) + bt(t+3) + ct(t+1)}{t(t+1)(t+3)} \\
&= \frac{(a+b+c)t^{2} + (4a+3b+c)t + 3a}{t(t+1)(t+3)}
\end{align}
$$
上記より$a+b+c=0, 4a+3b+c=0, 3a=6$が成立するので、$a=2, b=-3, c=1$を得ることができます。
・解説
部分分数分解は下記で詳しく取り扱いました。
Q.14
$$
\large
\begin{align}
f(x) = \int_{0}^{x} f(t) \sin{(x-t)} dt + ax + b \quad [1]
\end{align}
$$
$\sin{(x-t)} = \sin{x}\cos{t} – \cos{x}\sin{t}$より、$[1]$式は下記のように変形できる。
$$
\large
\begin{align}
f(x) &= \int_{0}^{x} f(t) \sin{(x-t)} dt + ax + b \quad [1] \\
&= \int_{0}^{x} f(t) (\sin{x}\cos{t} – \cos{x}\sin{t}) dt + ax + b \\
&= \sin{x} \int_{0}^{x} f(t) \cos{t} dt – \cos{x} \int_{0}^{x} f(t) \sin{t} dt + ax + b \quad [2]
\end{align}
$$
$[2]$式の両辺を$x$で微分すると下記が得られる。
$$
\large
\begin{align}
f'(x) &= \left[ \sin{x} \int_{0}^{x} f(t) \cos{t} dt – \cos{x} \int_{0}^{x} f(t) \sin{t} dt + ax + b \right] \quad [2]’ \\
&= \cos{x} \int_{0}^{x} f(t) \cos{t} dt + \cancel{f(x)\sin{x}\cos{x}} + \sin{x} \int_{0}^{x} f(t) \sin{t} dt – \cancel{f(x)\sin{x}\cos{x}} + a \\
&= \cos{x} \int_{0}^{x} f(t) \cos{t} dt + \sin{x} \int_{0}^{x} f(t) \sin{t} dt + a
\end{align}
$$
上記の両辺を$x$で微分すると下記が得られる。
$$
\large
\begin{align}
f^{”}(x) &= -\sin{x} \int_{0}^{x} f(t) \cos{t} dt + f(x) \cos^{2}{x} + \cos{x} \int_{0}^{x} f(t) \sin{t} dt + f(x) \sin^{2}{x} \\
&= – \left[ \sin{x} \int_{0}^{x} f(t) \cos{t} dt – \cos{x} \int_{0}^{x} f(t) \sin{t} dt \right] + (\cos^{2}{x} + \sin^{2}{x})f(x) \\
&= -(f(x) – ax – b) + f(x) = ax + b
\end{align}
$$
$f^{”}(x) = ax+b$の両辺を$x$で積分すると下記が得られる。
$$
\large
\begin{align}
f'(x) = \frac{a}{2}x^{2} + bx + C_1
\end{align}
$$
ここで$f'(0)=a$より、$C_1=a$が得られるので、$f'(x)$は下記のように表せる。
$$
\large
\begin{align}
f'(x) = \frac{a}{2}x^{2} + bx + a
\end{align}
$$
$f'(x) = \frac{a}{2}x^{2}+bx+a$の両辺を$x$で積分すると下記が得られる。
$$
\large
\begin{align}
f(x) = \frac{a}{6}x^{3} + \frac{b}{2}x^{2} + ax + C_2
\end{align}
$$
ここで$f(0)=b$なので$C_2=b$が得られる。よって、$f(x)$は下記のように表せる。
$$
\large
\begin{align}
f(x) = \frac{a}{6}x^{3} + \frac{b}{2}x^{2} + ax + b
\end{align}
$$
上記より、$(3)$が正しい。
Q.15
$$
\large
\begin{align}
A+B &= \left(\begin{array}{cc} 2 & 2 \\ -3 & 3 \end{array} \right) \quad [1] \\
A-B &= \left(\begin{array}{cc} 4 & 2 \\ 1 & -3 \end{array} \right) \quad [2]
\end{align}
$$
$[1]+[2]$より下記が得られる。
$$
\large
\begin{align}
(A+B) + (A-B) &= \left(\begin{array}{cc} 2 & 2 \\ -3 & 3 \end{array} \right) + \left(\begin{array}{cc} 4 & 2 \\ 1 & -3 \end{array} \right) \\
2A &= \left(\begin{array}{cc} 6 & 4 \\ -2 & 0 \end{array} \right) \\
A &= \left(\begin{array}{cc} 3 & 2 \\ -1 & 0 \end{array} \right)
\end{align}
$$
同様に$[1]-[2]$より下記が得られる。
$$
\large
\begin{align}
(A+B) – (A-B) &= \left(\begin{array}{cc} 2 & 2 \\ -3 & 3 \end{array} \right) – \left(\begin{array}{cc} 4 & 2 \\ 1 & -3 \end{array} \right) \\
2B &= \left(\begin{array}{cc} -2 & 0 \\ -4 & 6 \end{array} \right) \\
B &= \left(\begin{array}{cc} -1 & 0 \\ -2 & 3 \end{array} \right)
\end{align}
$$
よって行列の積$AB$は下記のように得られる。
$$
\large
\begin{align}
AB &= \left(\begin{array}{cc} 3 & 2 \\ -1 & 0 \end{array} \right) \left(\begin{array}{cc} -1 & 0 \\ -2 & 3 \end{array} \right) \\
&= \left(\begin{array}{cc} -7 & 6 \\ 1 & 0 \end{array} \right)
\end{align}
$$
上記より$(2)$が正しい。
Q.16
$$
\large
\begin{align}
A = \left(\begin{array}{ccc} 0 & 1-i & 1 \\ 1+i & 0 & 1-i \\ 1 & 1+i & 0 \end{array} \right)
\end{align}
$$
上記に対し、固有多項式$F_{A}(\lambda)=\det{(\lambda I_{3}-A)}$は下記のように計算できる。
$$
\large
\begin{align}
F_{A}(\lambda) &= \det{(\lambda I_{3}-A)} = \left| \begin{array}{ccc} -\lambda & 1-i & 1 \\ 1+i & -\lambda & 1-i \\ 1 & 1+i & -\lambda \end{array} \right| \\
&= -\lambda^{3} + (1+i)^{2} + (1-i)^{2} – \left[ -\lambda – 2 \lambda(1+i)(1-i) \right] \\
&= -\lambda^{3} + 1+i^2+\cancel{2i} + 1+i^2-\cancel{2i} + \lambda + 2 \lambda(1-i^2) \\
&= -\lambda^{3} + \cancel{1}-\cancel{1}+ + \cancel{1}-\cancel{1} + \lambda + 2 \lambda \cdot (1+1) \\
&= -\lambda^{3} + 5 \lambda
\end{align}
$$
よって、固有方程式$F_{A}(\lambda)=\det{(\lambda I_{3}-A)}=0$は下記のように解ける。
$$
\large
\begin{align}
F_{A}(\lambda) = -\lambda^{3} + 5 \lambda &= 0 \\
\lambda(\lambda^2-5) &= 0 \\
\lambda &= 0, \, \pm \sqrt{5}
\end{align}
$$
ここで$\lambda_{1}<\lambda_{2}<\lambda_{3}$であるので、$\lambda_{1}=-\sqrt{5}, \, \lambda_{2}=0, \, \lambda_{3}=\sqrt{5}$である。よって$\displaystyle \frac{\lambda_{1}}{2} + \frac{\lambda_{2}}{3} + \frac{\lambda_{3}}{4}$は下記のように計算することができる。
$$
\large
\begin{align}
\frac{\lambda_{1}}{2} + \frac{\lambda_{2}}{3} + \frac{\lambda_{3}}{4} &= -\frac{\sqrt{5}}{2} + \frac{\sqrt{5}}{4} \\
&= -\frac{\sqrt{5}}{4}
\end{align}
$$
したがって$(5)$が正しい。
・解説
$3$次以上の正方行列の行列式の計算にあたっては余因子展開を用いることが多い一方で、この問題では余因子展開を用いると$i$の取り扱いにあたって式が複雑になります。一般に$n$次の正方行列の行列式の計算にあたって出てくる項の数は$n!$個であるので、$3$次の場合はうまく使い分けると良いです。
Q.17
$$
\large
\begin{align}
X = \left(\begin{array}{cc} x & y \\ z & u \end{array} \right)
\end{align}
$$
上記のように$X$を表すと、$AX=XA$は下記のように表すことができる。
$$
\large
\begin{align}
AX &= XA \\
\left(\begin{array}{cc} a & b \\ c & d \end{array} \right) \left(\begin{array}{cc} x & y \\ z & u \end{array} \right) &= \left(\begin{array}{cc} x & y \\ z & u \end{array} \right) \left(\begin{array}{cc} a & b \\ c & d \end{array} \right) \\
\left(\begin{array}{cc} ax+bz & ay+by \\ cx+dz & cy+du \end{array} \right) &= \left(\begin{array}{cc} ax+cy & bx+dy \\ az+cu & bz+du \end{array} \right) \quad [1]
\end{align}
$$
$[1]$式より下記の連立方程式が得られる。
$$
\large
\begin{align}
\cancel{ax}+bz &= \cancel{ax}+cy \quad [2] \\
ay+by &= bx+dy \quad [3] \\
cx+dz &= az+cu \quad [4] \\
cy+\cancel{du} &= bz+\cancel{du} \quad [5]
\end{align}
$$
ここで$[2], [5]$式より、$bz=cy$が得られるが、この式が任意の$y,z$で成立する必要十分条件は$b=c=0$である。また、$b=c=0$を$[3], [4]$式に代入すると$a=d$が得られる。したがって$(4)$が正しい。
・解説
$a=d, \, b=c=0$は行列$A$が単位行列の定数倍を表すことも合わせて抑えておくと良いです。
Q.18
下記のように極限値を得ることができる。
$$
\large
\begin{align}
\lim_{x \to 0} \frac{\sin{bx}}{\sin{ax}} &= \lim_{x \to 0} \frac{\sin{bx}}{bx} \cdot \frac{ax}{\sin{ax}} \cdot \frac{b}{a} \\
&= 1 \cdot 1 \cdot \frac{b}{a} \\
&= \frac{b}{a}
\end{align}
$$
よって$(3)$が正しい。
・解説
この問題では$\displaystyle \lim_{\theta \to 0} \frac{\sin{\theta}}{\theta}=1$を用いました。$\displaystyle \lim_{\theta \to 0} \frac{\sin{\theta}}{\theta}=1$の導出は下記で取り扱ったので合わせて確認しておくと良いです。
Q.19
$$
\large
\begin{align}
f(x,y) = \tan^{1}{(ax+by+1)}, \quad a \neq 0, \, b \neq 0
\end{align}
$$
$2$変数関数$f(x,y)$のマクローリン展開は下記のように表せる。
$$
\begin{align}
f(x,y) = f(0,0) + \frac{1}{1!} \left( x \frac{\partial}{\partial x} + y \frac{\partial}{\partial y} \middle) f(x,y) \right|_{x=0,y=0} + \frac{1}{2!} \left( x \frac{\partial}{\partial x} + y \frac{\partial}{\partial y} \middle)^{2} f(x,y) \right|_{x=0,y=0} + \cdots
\end{align}
$$
上記より$xy$の係数は$\displaystyle \frac{\partial^{2}}{\partial x \partial y} f(x,y) \Bigr|_{x=0,y=0}$を計算することで得られる。ここで$\displaystyle (\tan^{-1}{x})’ = \frac{1}{1+x^2}$であるので、$xy$の係数は下記のように得られる。
$$
\large
\begin{align}
\frac{\partial^{2}}{\partial x \partial y} f(x,y) \Bigr|_{x=0,y=0} &= \frac{-2ab(ax+by+1)}{[1+(ax+by+1)]^{2}} \Bigr|_{x=0,y=0} \\
&= \frac{-2ab \cdot (0+0+1)}{[1+(0+0+1)]^{2}} \\
&= -\frac{2ab}{4} = -\frac{ab}{2}
\end{align}
$$
・解説
$\displaystyle (\tan^{-1}{x})’ = \frac{1}{1+x^2}$の導出は下記で取り扱いました。
Q.20
$$
\large
\begin{align}
2020 \times \frac{\displaystyle \int_{0}^{1} (1-x^{20})^{100} dx}{\displaystyle \int_{0}^{1} (1-x^{20})^{101} dx} \quad [1]
\end{align}
$$
$\displaystyle I_{n} = \int_{0}^{1} (1-x^{20})^{n} dx, \, n \geq 1$とおくと、部分積分法により下記のように漸化式が得られる。
$$
\large
\begin{align}
I_{n} &= \int_{0}^{1} (1-x^{20})^{n} dx \\
&= \left[ x(1-x^{20})^{n} \right]_{0}^{1} – \int_{0}^{1} x \cdot n(1-x^{20})^{n-1} \cdot (-20x^{19}) dx \\
&= 20n \int_{0}^{1} x^{20}(1-x^{20})^{n-1} dx \\
&= 20n \int_{0}^{1} (1-x^{20})^{n-1} dx – 20n \int_{0}^{1} (1-x^{20}) (1-x^{20})^{n-1} dx \\
&= 20n \int_{0}^{1} (1-x^{20})^{n-1} dx – 20n \int_{0}^{1} (1-x^{20})^{n} dx \\
&= 20n I_{n-1} – 20n I_{n} \\
(20n+1) I_{n} &= 20n I_{n-1} \\
I_{n} &= \frac{20n}{20n+1} I_{n-1} \quad [2]
\end{align}
$$
$[2]$式に$n=101$を代入すると下記が得られる。
$$
\large
\begin{align}
I_{101} &= \frac{20 \cdot 101}{20 \cdot 101 + 1} I_{101-1} \quad [2]’ \\
I_{101} &= \frac{2020}{2021} I_{100} \quad [3]
\end{align}
$$
$[3]$式より、$[1]$式は下記のように計算できる。
$$
\large
\begin{align}
2020 \times \frac{\displaystyle \int_{0}^{1} (1-x^{20})^{100} dx}{\displaystyle \int_{0}^{1} (1-x^{20})^{101} dx} &= 2020 \times \frac{I_{100}}{I_{101}} \\
&= 2020 \cdot I_{100} \cdot \frac{2021}{2020 I_{100}} \\
&= 2021
\end{align}
$$
上記より$(5)$が正しい。