
近年大きな注目を集めるChatGPTの学習にあたっては、強化学習に基づくRLHF(Reinforcement Learning from Human Feedback)がfinetuningに用いられます。当記事では同様の枠組みを取り扱ったInstructGPTの概要をまとめました。
作成にあたってはInstructGPTの論文である「Training language models to follow instructions with human feedback」を主に参考にしました。
・用語/公式解説
https://www.hello-statisticians.com/explain-terms
・InstructGPT論文
・仕組みから理解するChatGPT(筆者作成)
Contents
前提の確認
Transformer
下記で詳しく取り扱った。
・直感的に理解するTransformer
GPT-3
下記で詳しく取り扱った。
PPOを用いた強化学習
PPO(Proximal Policy Optimization)は方策勾配法(Policy Gradient)の学習の安定化にあたって、繰り返し演算におけるパラメータの修正幅を制限する手法である。詳しくは下記で取り扱った。
InstructGPT
大まかな流れ
大まかな流れは下記のInstructGPT論文Figure$2$を元に理解すると良い。
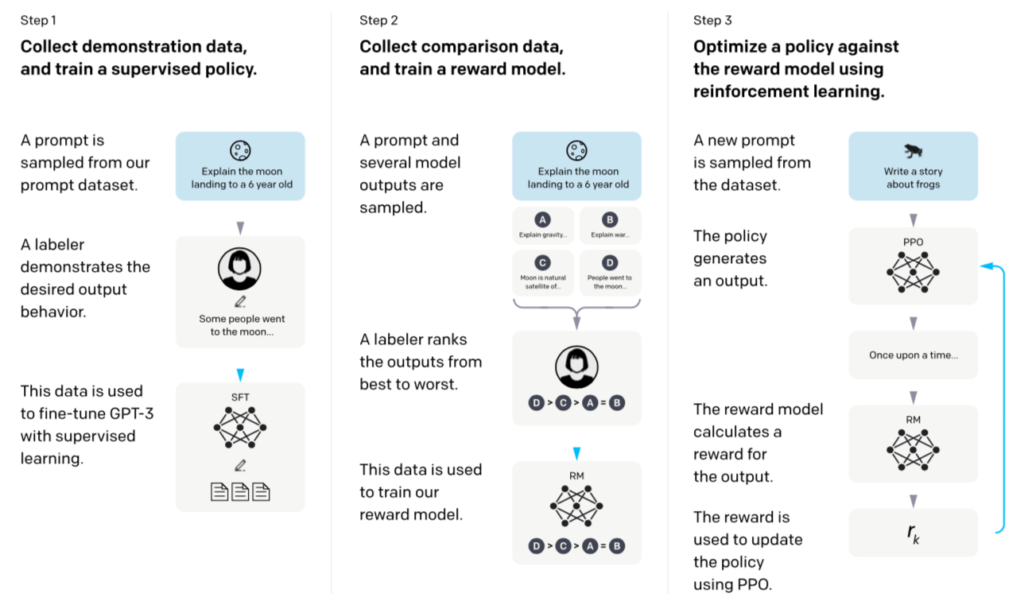
上図より、InstructGPTの大まかな流れは下記の$3$つのステップで表される。
$1. \,$ プロンプトの入力例に対し人間が正解例を作成し、教師あり学習の形式でGPT-$3$のfinetuningを行う。
$2. \,$ 複数のプロンプトの出力結果に対し、人間がランク付けを行い、RewardModelを学習させる。
$3. \,$ 学習させたRewardModelを元にプロンプトの出力結果に対しRewardを出力し、この値に応じて文の生成における方策をPPOを用いて強化学習させる。
上記の『プロンプト』はGPT-$3$に対しfinetuningと方策の最適化を行なったInstructGPTの入出力に対応することに注意が必要である。以下では$1.$〜$3.$についてそれぞれ詳しく確認を行う。
$1.$ Supervised Fine-Tuning
InstructGPTでは学習済みのGPT-$3$に対し、教師ありFine-Tuning(SFT; Supervised Fine-Tuning)を行う。具体的には人間(labeler)がプロンプトの入力例に対し回答を作成し、その内容に基づいてFine-Tuningを行う。
SFTでは基本的に教師あり学習と同様の手順で学習を行うが、学習済みのGPT-$3$を用いることから教師なし学習を十分に行ったのちの処理であることは注意して抑えておくと良い。
$2.$ RewardModel
RewardModel論文
InstructGPTのRewardModelには「Learning to summarize from human feedback」のRewardModelと同様なものが用いられる。よって以下ではこのRewardModel論文を元に取りまとめを行う。
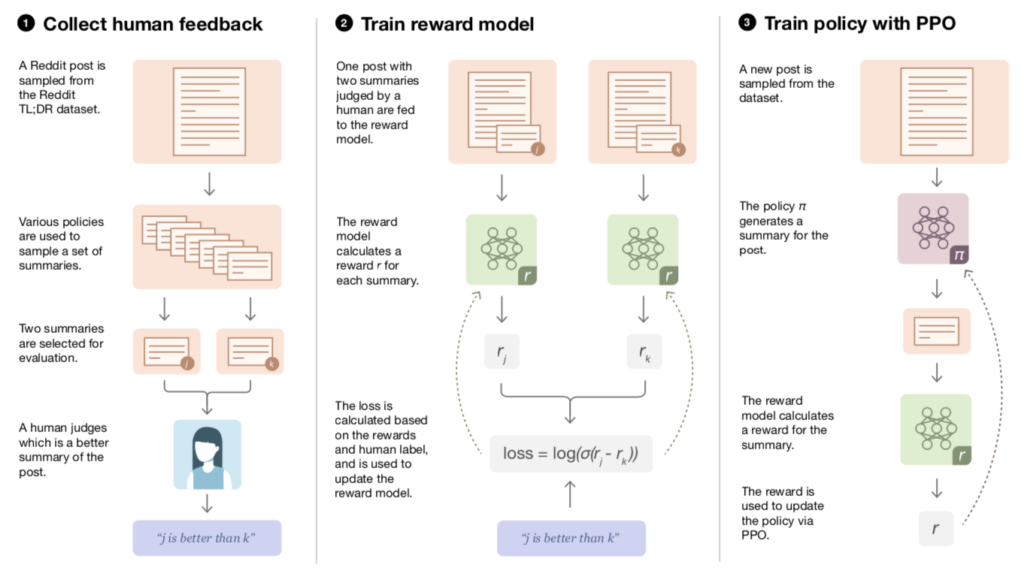
上記はRewardModel論文のFigure$2$であるが、$2.$と$3.$はInstructGPT論文の図と概ね同様であることが確認できる。一方で、RewardModel論文の$2.$には下記の数式でRewardModelのlossの記載があることにも注意しておくと良い。
$$
\large
\begin{align}
\mathrm{loss} = \log{[\sigma(r_j-r_k)]} \quad (1)
\end{align}
$$
$(1)$式における$r_j$は人間が選んだもの、$r_k$はそうでないものがそれぞれ対応する。論文の本文では$(1)$式と同じlossが下記のように表される。
$$
\large
\begin{align}
\mathrm{loss}(r_{\theta}) = -\mathbb{E}_{(x,y_0,y_1,i) \sim D} \left[ \log{(\sigma[r_{\theta}(x,y_i)-r_{\theta}(x,y_{1-i})])} \right] \quad (1)’
\end{align}
$$
RewardModelのlossの解釈
当項では以下、前項の「RewardModel」のlossである$(1)$式がクロスエントロピーに対応することに関して確認を行う。二値分類におけるクロスエントロピー誤差関数は下記で表すベルヌーイ分布$\mathrm{Bern}(p)$の確率関数$f(x)$から導出できる。
$$
\large
\begin{align}
f(x) = p^{x} (1-p)^{1-x}
\end{align}
$$
上記をパラメータ$p$に関する尤度$L(p)$と見なすと、$-\log{L(p)}$は下記のように表せる。
$$
\large
\begin{align}
-\log{L(p)} &= -\log{(p^{x} (1-p)^{1-x})} \\
&= – x \log{p} \, – \, (1-x) \log{(1-p)} \quad (2)
\end{align}
$$
$(2)$式は二値分類におけるクロスエントロピー誤差関数に一致する。ここで$x=1$が観測されたと仮定すると$1-x=0$であるので、$(2)$式は下記のように表すことができる。
$$
\large
\begin{align}
-\log{L(p)} &= – 1 \cdot \log{p} \, – \, (1-1) \log{(1-p)} \quad (2)’ \\
&= -\log{p} \quad (3)
\end{align}
$$
ここで一般化線形モデル(GLM; Generalized Linear Model)と同様の要領で、$p$をニューラルネットワークの出力と対応させることを考える。RewardModel論文では下記のような式に基づいて確率パラメータ$p$の予測を行う。
$$
\large
\begin{align}
p &= \sigma(r_j-r_k) \quad (4) \\
\sigma(x) &= \frac{1}{1+\exp(-x)}
\end{align}
$$
$\sigma(x)$はシグモイド関数に対応する。$(4)$式の解釈にあたって、シグモイド関数の定義に基づいて下記のような変換を行う。
$$
\large
\begin{align}
p &= \sigma(r_j-r_k) \quad (4) \\
&= \frac{1}{1+\exp{[-(r_j-r_k)]}} \\
&= \frac{1}{1+\exp{(-r_j+r_k)}} \\
&= \frac{\exp{(r_j)}}{\exp{(r_j)}+\exp{(r_j-r_j+r_k)}} \\
&= \frac{\exp{(r_j)}}{\exp{(r_j)}+\exp{(r_k)}} \quad (5)
\end{align}
$$
$(5)$式は出力層で$r_j, r_k$が得られた際にソフトマックス関数を計算することに対応する。$(3),(5)$式より、$(1)$式がクロスエントロピー誤差関数であり、かつ報酬を出力するネットワークをソフトマックス関数と同様の式に基づいて学習させると解釈できる。
$3.$ Reinforcement learning
目的関数
InstructGPTにおける強化学習では強化学習によって得られる方策の$\pi_{\phi}^{\mathrm{RL}}$とSupervised Fine-Tuningによって得られた$\pi_{\phi}^{\mathrm{SFT}}$を元に、下記のような目的関数を用いて学習を行う。
$$
\large
\begin{align}
\mathrm{Objective}(\phi) = E_{(x,y) \sim D’} \left[ r_{\theta}(x,y) – \beta \log{\frac{\pi_{\phi}^{\mathrm{RL}}(y|x)}{\pi_{\phi}^{\mathrm{SFT}}(y|x)}} \right] + \gamma E_{x \sim D} \left[ \log{(\pi_{\phi}^{\mathrm{RL}}(x))} \right] \quad (6)
\end{align}
$$
上記の$D’$は新たなプロンプトの入力である$x$と強化学習の結果生成される$y$に対応し、$r_{\theta}(x,y)$はRewardModelの出力、$\displaystyle \beta \log{ \frac{\pi_{\phi}^{\mathrm{RL}}(y|x)}{\pi_{\phi}^{\mathrm{SFT}}(y|x)} }$はPPO論文などのKL penaltyにそれぞれ対応する。また、$D$はpre-trainingの際に用いたコーパスであり、$\displaystyle E_{x \sim D} \left[ \log{(\pi_{\phi}^{\mathrm{RL}}(x))} \right]$は元々のpre-trainの結果から大きく変わった結果が得られないように設定される。
ここで$\gamma$は事前学習+SFTの結果との一貫性に対応する係数であり、InstructGPT論文では$\gamma=0$のときを”PPO”、$\gamma \neq 0$のときを”PPO-ptx”と表す。また、InstructGPT論文ではInstructGPTが”PPO-ptx”に対応するとされる。
a per-token KL penalty
$$
\large
\begin{align}
\log{ \frac{\pi_{\phi}^{\mathrm{RL}}(y|x)}{\pi_{\phi}^{\mathrm{SFT}}(y|x)} } \quad (7)
\end{align}
$$
上記の式はKL penaltyの期待値の内部に対応するが、$y$が系列であるので以下、per-tokenの形式への変形を行う。式変形にあたって、$y=(y_1, \cdots , y_N)$のように表す。このとき、$y_i$より前の系列を$\mathbf{y}_{:i}$とおくと、$(7)$式は下記のように変形できる。
$$
\large
\begin{align}
\log{ \frac{\pi_{\phi}^{\mathrm{RL}}(y|x)}{\pi_{\phi}^{\mathrm{SFT}}(y|x)} } &= \log{ \frac{\displaystyle \prod_{i=1}^{N} \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}{\displaystyle \prod_{i=1}^{N} \pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})} } \\
&= \sum_{i=1}^{N} \log{ \frac{\displaystyle \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}{\displaystyle \pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})} } \quad (8)
\end{align}
$$
ここで$(8)$式の期待値を取ることでa per-token KL penaltyを表すことができる。また、上記では$i=1$のとき$\mathbf{y}_{:i}$は存在せず、$i=2$のとき$\mathbf{y}_{:i}=(y_1)$、$i \geq 3$のとき$\mathbf{y}_{:i}=(y_1, \cdots , y_{i-1})$が対応することに注意が必要である。
目的関数の勾配
以下、$(6)$式の勾配の計算について取り扱う。
$$
\large
\begin{align}
\mathrm{Objective}(\phi) = E_{(x,y) \sim D’} \left[ r_{\theta}(x,y) – \beta \log{\frac{\pi_{\phi}^{\mathrm{RL}}(y|x)}{\pi_{\phi}^{\mathrm{SFT}}(y|x)}} \right] + \gamma E_{x \sim D} \left[ \log{(\pi_{\phi}^{\mathrm{RL}}(x))} \right] \quad (6)
\end{align}
$$
まず、$\displaystyle E_{(x,y) \sim D’} \left[ r_{\theta}(x,y) \right]$の$\phi$に関する勾配の計算は$r_{\theta}(x,y)$が定数であることに基づいて、下記のように得られる。
$$
\large
\begin{align}
\nabla_{\phi} E_{(x,y) \sim D’} \left[ r_{\theta}(x,y) \right] = E_{(x,y) \sim D’} \left[ \sum_{i=1}^{N} r_{\theta}(x,y) \nabla_{\phi} \log{\pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})} \right]
\end{align}
$$
上記は方策勾配法の基本的な勾配の計算と同様である。式の理解にあたっては収益$r_{\theta}(x,y)$の大きさに応じてパラメータ$\phi$の修正量を調整すると解釈すればよい。詳しい導出の流れや式の解釈は下記で取り扱った。
次にa per-token KL penaltyの勾配の計算を行う。式の簡略化にあたって、下記のように表した$(6), (8)$式に基づく$1$トークン分のKL penaltyの勾配を計算する。
$$
\large
\begin{align}
E_{(x,y) \sim D’} \left[ \log{ \frac{\displaystyle \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}{\displaystyle \pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})} } \right] = \sum_{y_i} \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i}) \log{ \frac{\displaystyle \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}{\displaystyle \pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})} } \quad (9)
\end{align}
$$
$(9)$式の$\displaystyle \sum_{y_i}$の中の項に関して$\nabla_{\phi}$を用いて勾配は下記のように計算できる。
$$
\large
\begin{align}
& \nabla_{\phi} \left[ \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i}) \log{ \frac{\displaystyle \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}{\displaystyle \pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})} } \right] \\
&= \nabla_{\phi} \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i}) \log{ \frac{\displaystyle \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}{\displaystyle \pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})} } + \cancel{\pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})} \cdot \left( \frac{\displaystyle \cancel{\pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}}{\displaystyle \cancel{\pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})}} \right)^{-1} \cdot \frac{\displaystyle \nabla_{\phi} \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}{\displaystyle \cancel{\pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})}} \\
&= \nabla_{\phi} \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i}) \left[ 1 + \log{ \frac{\displaystyle \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}{\displaystyle \pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})} } \right] \quad (10)
\end{align}
$$
計算にあたってはSFTのパラメータ$\phi$が固定であることから定数であるとみなした。$(8)$式と$(10)$式を元に$(6)$式を見ると、$(10)$式の勾配の逆向きにパラメータ$\phi$をUpdateすることが確認できる。ここで$\displaystyle \frac{\displaystyle \pi_{\phi}^{\mathrm{RL}}(y_{i}|x,\mathbf{y}_{:i})}{\displaystyle \pi_{\phi}^{\mathrm{SFT}}(y_i|x,\mathbf{y}_{:i})}$の大きさに応じて勾配に基づく修正量を調整することが確認できるので、RLとSFTの確率が同様な場合は修正量が小さくなりペナルティが小さいと解釈できる。
InstructGPTまとめ
InstructGPTは①SFT、②RewardModel、③ReinforcementLearning(PPO, KL penalty)に基づいて学習済みのGPT-$3$に対し追加の学習を行う手法である。
[…] InstructGPTの概要まとめ 〜GPT3、RLHF、RewardModel〜 […]