
GPT-$3$はTransformerに基づくLLMの$1$つであり、近年大きな注目を集めるChatGPTなど、幅広く用いられます。当記事ではGPT-$3$の論文である、Language Models are Few-Shot Learnersの取りまとめを行いました。
・用語/公式解説
https://www.hello-statisticians.com/explain-terms
Contents
前提の確認
Transformer
下記で詳しく取り扱った。
・直感的に理解するTransformer
Transformer Decoder
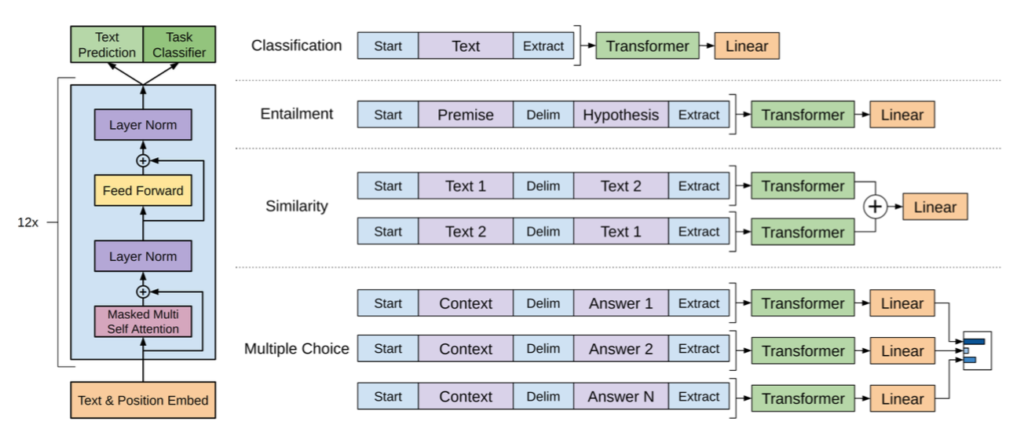
オリジナルのTransformerではEncoder Decoderに基づいて構成されるが、GPT-$3$ではTransformerのDecoderのみを用いる。この構成の元になったのがTransformer Decoderの論文である。
Pre-training
GPT、GPT-$2$、GPT-$3$ではトークン列$x_0, \cdots x_n$が得られたとき、下記のように定義する対数尤度を元に教師なし事前学習(Unsupervised Pre-Training)を行う。
$$
\large
\begin{align}
\log{L(\Theta)} &= \log{ P(x_0|\Theta) \prod_{i=1}^{n} P(x_i|\mathbf{x}_{:(i-1)},\Theta) } \\
&= \log{P(x_0|\Theta)} + \sum_{i=1}^{n} \log{P(x_i|\mathbf{x}_{:(i-1)},\Theta)} \\
\mathbf{x}_{:0} &= (x_0), \quad \mathbf{x}_{:(i-1)} = (x_0, \cdots , x_{i-1}), \, i \geq 1
\end{align}
$$
上記の対数尤度の最大化は教師なし学習であり単にテキストがあれば良いので、Wikipediaのような巨大なコーパスを用いて学習を行うことができる。
ここではGPT論文(Improving Language Understanding by Generative Pre-Training)に基づいて数式を定義したが、BERTの事前学習であるMLM(Masked Lauguage Model)と基本的には同様なカテゴリで理解しておくと良い。
GPT-$3$
Fine-Tuning
Pre-trainingによって得られた学習済みモデルのパラメータ(weights)を特定のタスクの教師ありデータセットに基づいて追加学習を行う一連のプロセスをFine-Tuningという。
Fine-TuningはDeepLearningの多くの分野で広く用いられているテクニックである一方で、GPT-$3$ではFine-Tuningを用いる代わりに次項で取り扱うZero-Shot・One-Shot・Few-Shotを元に追加学習を行う。
Zero-Shot・One-Shot・Few-Shot
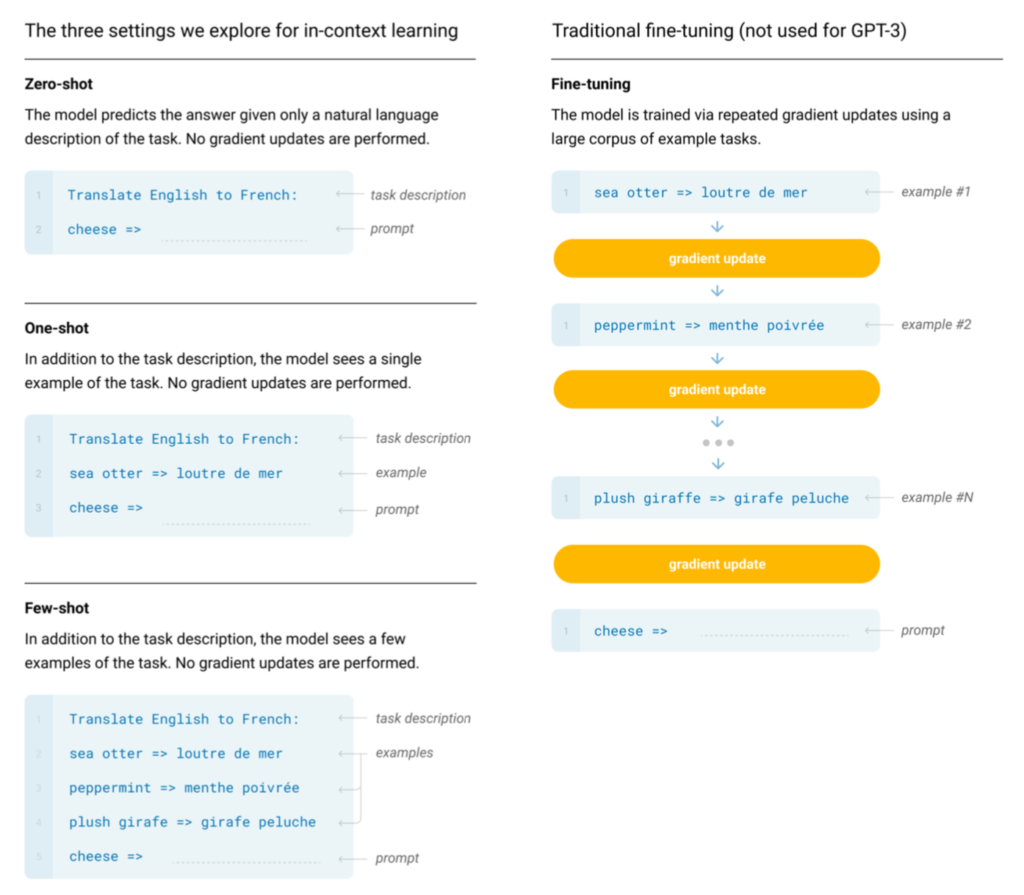
ここで”Shot”は推論の際に入力する”Example”に相当し、Zero-Shotはタスクのみ、One-Shotはタスク+$1$例、Few-Shotはタスク+数例の入力にそれぞれ対応する。具体的には下記のような入力と出力が対応するように学習を行う。

[…] 【GPT-3】Language Models are Few-Shot Learners まとめ […]