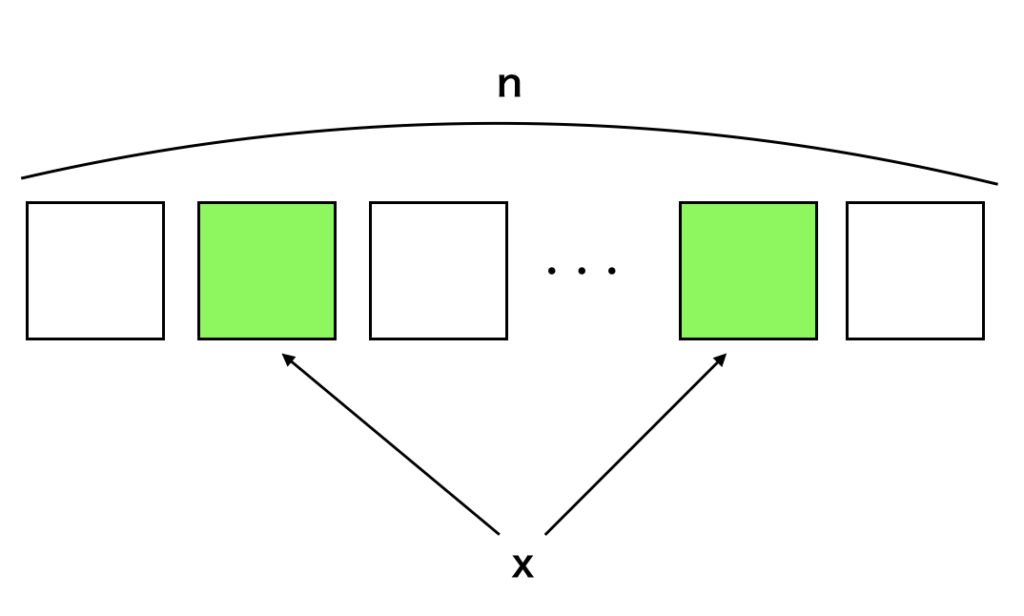
$$ \large \begin{align} \vec{x}_{n+p} = \vec{x}_{n+q} + \vec{x}_{n+1} B + \vec{x}_{n} C \quad (\mathrm{mod} \; 2, \; q<p) \end{align} $$
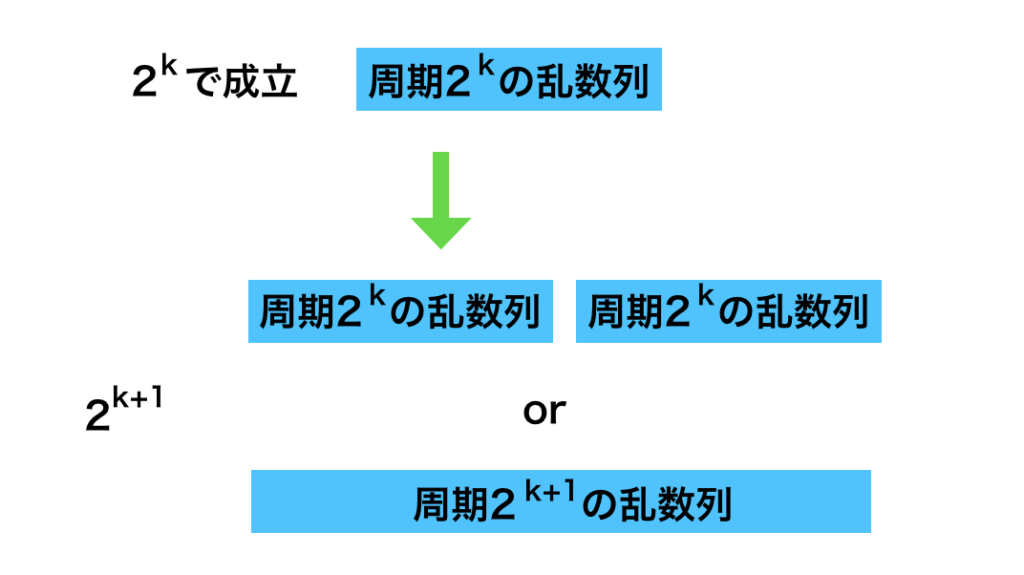
メルセンヌ・ツイスタ法は上記の漸化式で表される。$B, C$に関しては「$\vec{x}_{n+1} B + \vec{x}_{n} C$」が「$\vec{x}_{n}$の上位$w-r$ビットと$\vec{x}_{n+1}$の下位$r$ビットで構成したビットを$\vec{x}_{n}’$とおくとき、$\vec{x}_{n}’=(\vec{x}_{n+1} B + \vec{x}_{n} C)A$が成立するような行列」と理解すると良い。このように生成した乱数は$2^{wp-r}-1$の最大周期を実現できる。
/* A C-program for TT800 : July 8th 1996 Version */
/* by M. Matsumoto, email: matumoto@math.keio.ac.jp */
/* genrand() generate one pseudorandom number with double precision */ /* which is uniformly distributed on [0,1]-interval */
/* for each call. One may choose any initial 25 seeds */
/* except all zeros. */
/* See: ACM Transactions on Modelling and Computer Simulation, */
/* Vol. 4, No. 3, 1994, pages 254-266. */
#include <stdio.h>
#define N 25
#define M 7
double
genrand()
{
unsigned long y;
static int k = 0;
static unsigned long x[N]={ /* initial 25 seeds, change as you wish */
0x95f24dab, 0x0b685215, 0xe76ccae7, 0xaf3ec239, 0x715fad23,
0x24a590ad, 0x69e4b5ef, 0xbf456141, 0x96bc1b7b, 0xa7bdf825,
0xc1de75b7, 0x8858a9c9, 0x2da87693, 0xb657f9dd, 0xffdc8a9f,
0x8121da71, 0x8b823ecb, 0x885d05f5, 0x4e20cd47, 0x5a9ad5d9,
0x512c0c03, 0xea857ccd, 0x4cc1d30f, 0x8891a8a1, 0xa6b7aadb
};
static unsigned long mag01[2]={
0x0, 0x8ebfd028 /* this is magic vector ‘a’, don’t change */
};
if (k==N) { /* generate N words at one time */
int kk;
for (kk=0;kk<N-M;kk++) {
x[kk] = x[kk+M] ^ (x[kk] >> 1) ^ mag01[x[kk] % 2];
}
for (; kk<N;kk++) {
x[kk] = x[kk+(M-N)] ^ (x[kk] >> 1) ^ mag01[x[kk] % 2];
}
k=0; }
y = x[k];
y ^= (y << 7) & 0x2b5b2500; /* s and b, magic vectors */
y ^= (y << 15) & 0xdb8b0000; /* t and c, magic vectors */
y &= 0xffffffff; /* you may delete this line if word size = 32 */
y ^= (y >> 16); /* added to the 1994 version */
k++;
return( (double) y / (unsigned long) 0xffffffff);
}
/* this main() output first 50 generated numbers */
main()
{ int j;
for (j=0; j<50; j++) {
printf("%5f ", genrand());
if (j%8==7) printf("\n");
}
printf("\n");
}
import numpy as np
import matplotlib.pyplot as plt
init_x = [bin(0x95f24dab), bin(0x0b685215), bin(0xe76ccae7), bin(0xaf3ec239), bin(0x715fad23), bin(0x24a590ad), bin(0x69e4b5ef), bin(0xbf456141), bin(0x96bc1b7b), bin(0xa7bdf825), bin(0xc1de75b7), bin(0x8858a9c9), bin(0x2da87693), bin(0xb657f9dd), bin(0xffdc8a9f), bin(0x8121da71), bin(0x8b823ecb), bin(0x885d05f5), bin(0x4e20cd47), bin(0x5a9ad5d9), bin(0x512c0c03), bin(0xea857ccd), bin(0x4cc1d30f), bin(0x8891a8a1), bin(0xa6b7aadb)]
x = np.zeros([100000, 2**5])
for i in range(len(init_x)):
init_num = 2**5-len(list(init_x[i][2:]))
x[i,init_num:] = np.array(list(init_x[i][2:]))
a = bin(0x8ebfd028)
init_num_a = 2**5-len(list(a[2:]))
A = np.zeros([2**5, 2**5])
for i in range(A.shape[0]-1):
A[i,i+1] = 1.
A[-1,init_num_a:] = np.array(list(a[2:]))
for i in range(x.shape[0]-25):
x[i+25,:] = (x[i+7,:] + np.dot(x[i,:],A))%2
numbers = np.zeros(x.shape[0])
for i in range(x.shape[0]):
for j in range(x.shape[1]):
numbers[i] += x[i,j]*2**(2**5-1-j)
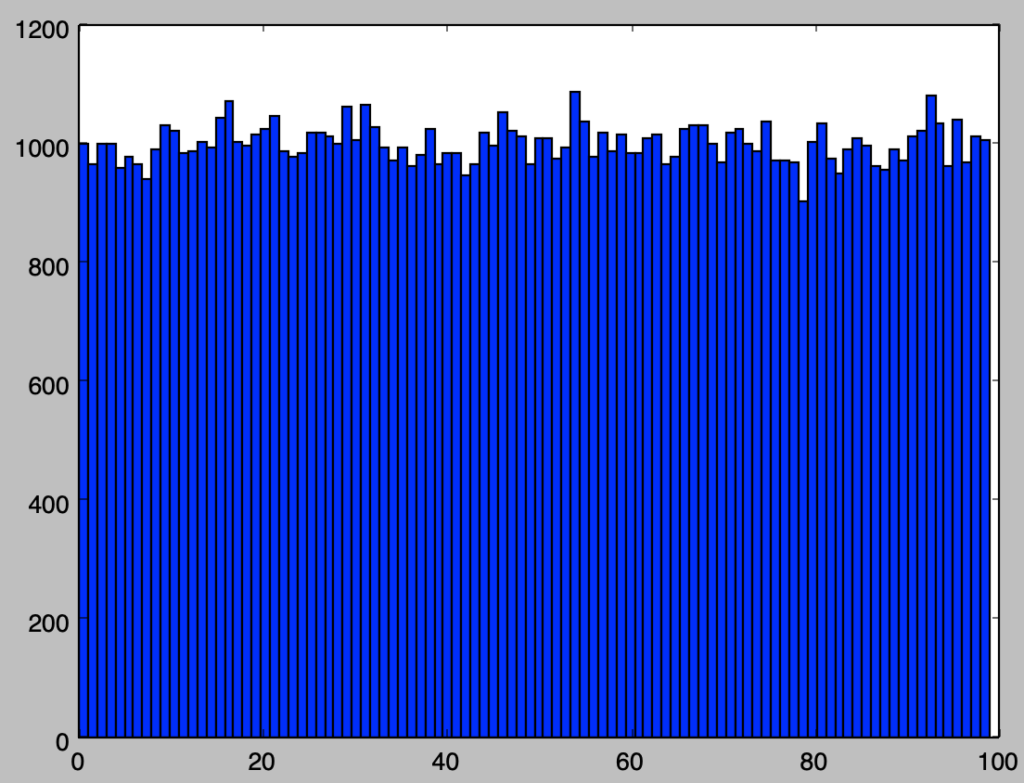
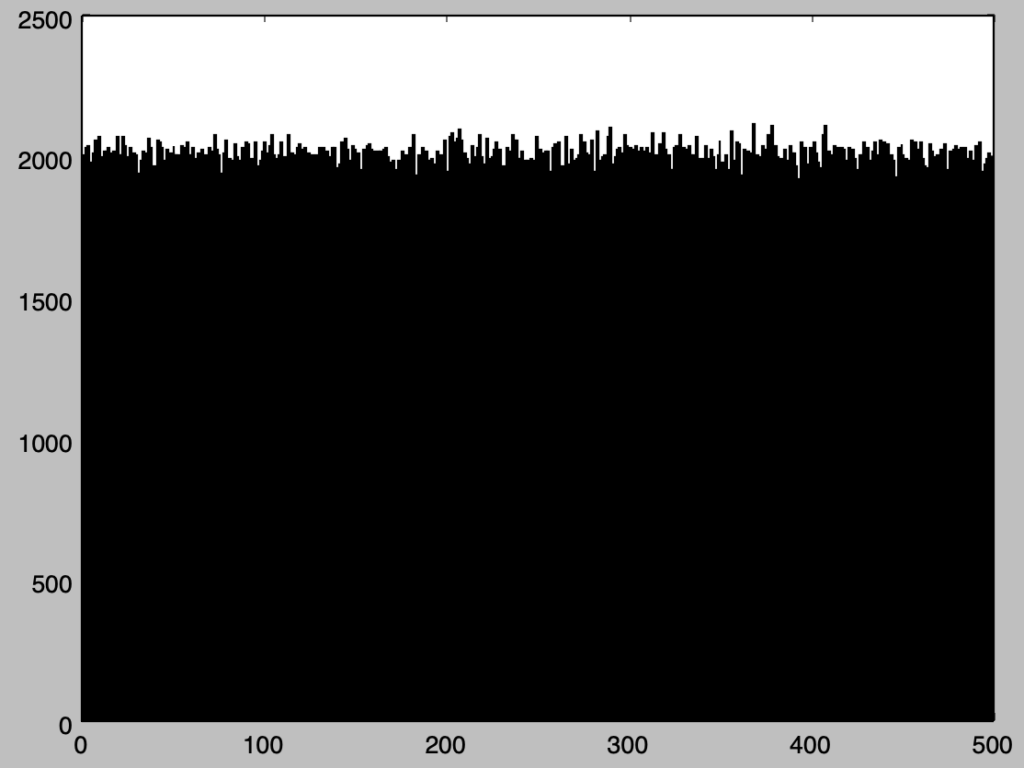
plt.hist(numbers%100, bins=100)
plt.show()