
PointNet++を用いた点群の処理はPointNetに階層型のプーリングを導入することで改良にはなったものの、局所領域における点間の相関を取り扱えないなどの課題があります。当記事ではこの課題の解決にあたって点群の処理にTransformerを導入したPointformerについて取りまとめました。
Pointformerの論文である「$3$D Object Detection with Pointformer」の内容を参考に作成を行いました。
・用語/公式解説
https://www.hello-statisticians.com/explain-terms
Contents
前提の確認
Transformerの概要
Dot Product Attentionに主に基づくTransformerの仕組みについては既知である前提で当記事はまとめました。下記などに解説コンテンツを作成しましたので、合わせて参照ください。
・直感的に理解するTransformerの仕組み(統計の森作成)
PointNet
PointNet++
Pointformer
処理の概要
Pointformerの処理の全体像は下図を元に掴むと良いです。
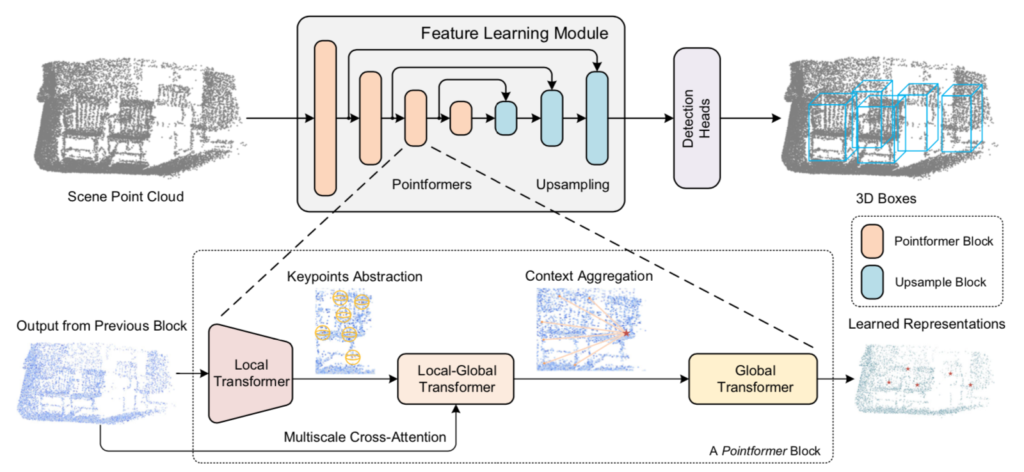
上図から確認できるように、Pointformerは「Pointformer Block」に基づいて基本的に構成されています。
また、同時に「Pointformer Block」が「Local Transformer」、「Local-Global Transformer」、「Global Transformer」の三つの処理から構成されていることも確認することができます。以下、三つの処理について詳しく確認を行います。
Local Transformer
入力される点群の集合を$\mathcal{P} = \{ x_1, \cdots , x_{N} \}$とおくとき、Local TransformerではPointNet++と同様にFPS(Furthest Point Sampling)を用いて下記のような中心点の集合を取得します。
$$
\large
\begin{align}
\{ x_{c_1}, \cdots , x_{c_{N’}} \}, \quad N’ < N
\end{align}
$$
このとき、上記の中心点の周辺の半径に基づいたball queryを用いることで$j$番目の中心点に対して$K_t(t=1, \cdots , N’)$個の点を獲得し、Transformerへ入力を行います。
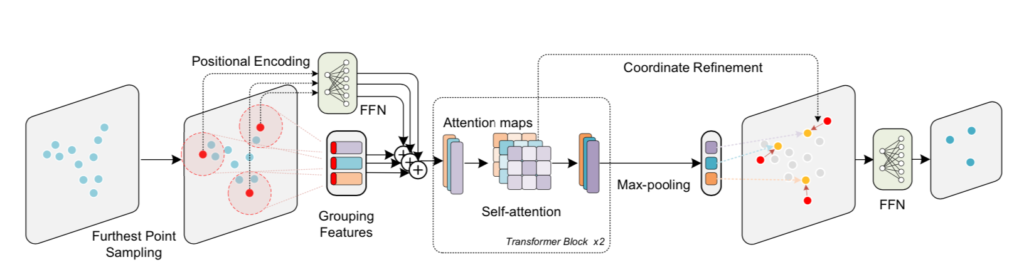
FPSは上図における左側の青丸から赤丸を取得する処理、ball queryを用いた処理は赤丸の中心に基づいて円を描き、円の内部の点をグルーピングする処理にそれぞれ対応します。
$t$番目の中心点の周囲の局所領域における$i$番目の点について位置情報と特徴量を$\{ x_{i}, f_{i} \}_{t}, \, x_{i} \in \mathbb{R}^{1 \times 3}, \, f_{i} \in \mathbb{R}^{1 \times C}$のように表すとき、$t$番目の領域におけるTransformer処理は下記のように表すことができます。
$$
\large
\begin{align}
f_{i}^{(0)} &= \mathrm{FFN}(f_{i}), \quad {}^{\forall} i \in N(x_{c_{t}}) \\
F^{(l+1)} &= \mathrm{Transformer Block}(F^{(l)}, \mathrm{PE}(X)) \\
F^{(l)} &= \left( \begin{array}{c} f_{1}^{(l)} \\ \vdots \\ f_{K_t}^{(l)} \end{array} \right) , \quad X = \left( \begin{array}{c} x_{1} \\ \vdots \\ x_{K_t} \end{array} \right)
\end{align}
$$
ここで$N(x_{c_{t}})$の$N$は中心点$x_{c_{t}}$と同じ領域にグルーピングされた点のインデックスの集合を表します1。$\mathrm{Transformer Block}$は一般的なTransformerのそれぞれの層における計算に対応します。また、論文では$F^{(l)},X$がやや唐突に出てきたので上記の$3$式目で具体化しました。
ここまでがLocal Transformerの基本処理です。一方で、Local Transformerには基本処理に加えてFPSによってサンプリングされた中心点の位置の補正を行うCoordinate Refinementも合わせて用いられます。以下、Coordinate Refinementについて詳しく確認します。
Coordinate RefinementはLocal Transformerで計算を行ったAttention Matrix2に基づいて中心点の位置の調整を行う手法です。Attention Matrixの$m$番目のheadのAttention Matrixを$A^{(m)}$、$t$番目の中心点に対応する行を$A_{c}^{(m)} \in \mathbb{R}^{1 \times K_t}$とおくとき、行ベクトル$\mathbf{w} \in \mathbb{R}^{1 \times K_t}$を下記のように定義します。
$$
\large
\begin{align}
\mathbf{w} = \frac{1}{M} \sum_{m=1}^{M} A_{c}^{(m)}
\end{align}
$$
上記の$M$はMultiHead Attentionにおけるheadの数を表します。このとき、行ベクトル$\mathbf{w}$の$k$番目の要素を$w_{k}$のように表すとき、中心点$x_{c_{t}}$を下記のような式に基づいて得られる$x’_{c_{t}}$に移動させます3。
$$
\large
\begin{align}
x_{c_{t}}’ &= \sum_{k=1}^{K_{t}} w_{k} x_{k} \\
w_{k} & \in \mathbb{R}, \, x_{c_{t}}’ \in \mathbb{R}^{1 \times 3}, \, x_{k} \in \mathbb{R}^{1 \times 3}
\end{align}
$$
Local-Global Transformer
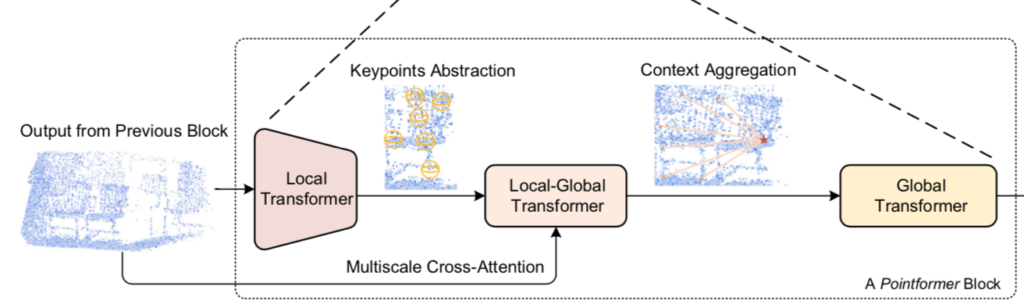
Local-Transformerでは中心点に基づく局所領域を元に点群のダウンサンプリングを行います。この処理では局所領域におけるattentionしか計算しないので、ダウンサンプリング後のそれぞれの点に対して大域的な情報を反映させられることが望ましいです。
Local-Global Transformerではダウンサンプリング後の各点に対して大域的な情報を反映させるにあたって、Local Transformerの出力をquery、Pointformer blockへの入力をkey・valueとするcross-attention処理を行います。Pointformer blockへの入力は高解像度なので点のインデックスの集合を$\mathcal{P}^{h}$、Local Transformerの出力低解像度なので点のインデックスの集合を$\mathcal{P}^{l}$とおくと、Local-Global Transformerの演算を下記のように表すことができます。
$$
\large
\begin{align}
f_{i}^{(0)} &= \mathrm{FFN}(f_{i}), \quad {}^{\forall} i \in \mathcal{P}^{l} \\
f_{j}’ &= \mathrm{FFN}(f_{j}), \quad {}^{\forall} j \in \mathcal{P}^{h} \\
F^{(l+1)} &= \mathrm{Transformer Block}(F^{(l)}, F’, \mathrm{PE}(X)) \\
F^{(l)} &= \left( \begin{array}{c} f_{1}^{(l)} \\ \vdots \\ f_{K_t}^{(l)} \end{array} \right), \quad X = \left( \begin{array}{c} x_{1} \\ \vdots \\ x_{K_t} \end{array} \right) \\
F’ &= \left( \begin{array}{c} f_{1}’ \\ \vdots \\ f_{N}’ \end{array} \right)
\end{align}
$$
上記の式の$\mathrm{Transformer Block}$はself-attentionではなくcross-attentionの式であることに注意が必要です。
Global Transformer
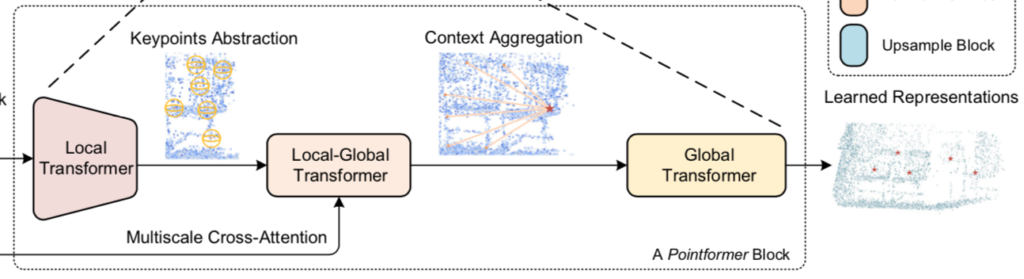
Global TransformerではLocal-Global Transformerの出力の全ての点のインデックスの集合$\mathcal{P}$についてTransformer処理を行います。
$$
\large
\begin{align}
f_{i}^{(0)} &= \mathrm{FFN}(f_{i}), \quad {}^{\forall} i \in \mathcal{P} \\
F^{(l+1)} &= \mathrm{Transformer Block}(F^{(l)}, \mathrm{PE}(X))
\end{align}
$$
Global Transformerの式表記はLocal Transformerの$N(x_{c_{t}})$を$\mathcal{P}$に変えることで表されます。
Pointformerの構成
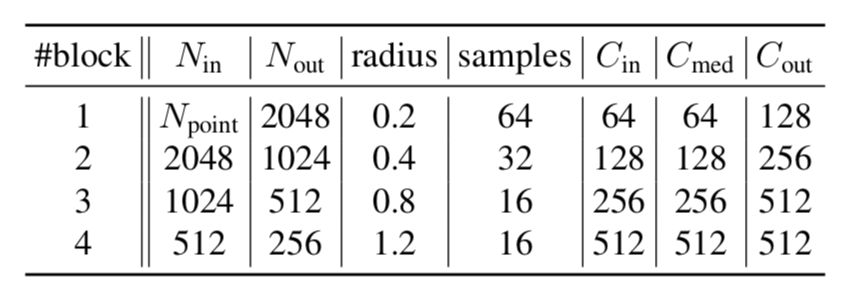
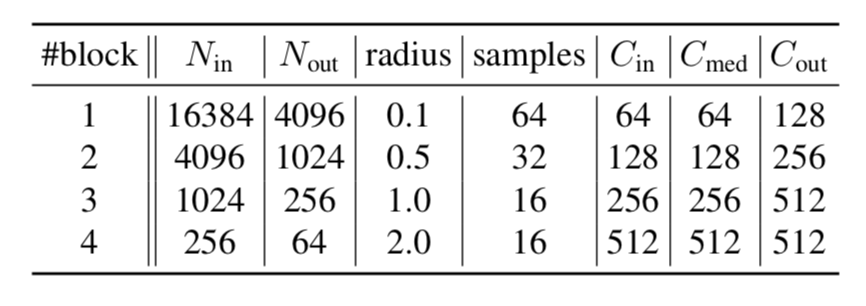
indoorデータセットとKITTIに対するPointformerの構成は下記の表より確認することができます。
参考
・Transformer論文:Attention is All you need[$2017$]
・Pointformer論文