
Segmentationタスクには従来VGGNetやResNetなどのCNNをbackboneに持つネットワークを用いることが主流であった一方で、近年Transformerの導入も行われています。当記事ではSemantic SegmentationにTransformerを導入した研究であるSETRについて取りまとめました。
SETRの論文である「Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers」の内容を参考に作成を行いました。
・用語/公式解説
https://www.hello-statisticians.com/explain-terms
Contents
前提の確認
Transformerの概要
Dot Product Attentionに主に基づくTransformerの仕組みについては既知である前提で当記事はまとめました。下記などに解説コンテンツを作成しましたので、合わせて参照ください。
・直感的に理解するTransformerの仕組み(統計の森作成)
ViT
SETR
処理の概要
SETR(Segmentation TRansformer)の処理の概要は下図より確認できます。
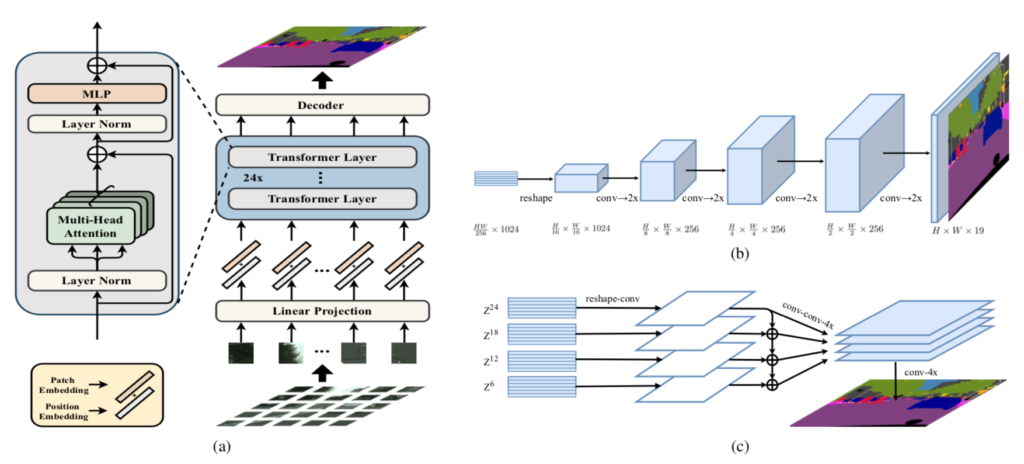
上図の$(\mathrm{a})$より、SETRにおける処理の全体像が確認できます。基本的な処理構造はTransformer・ViTと同様な構成です。一方、DecoderではSegmentationタスク用の処理が行われており、$(\mathrm{b})$ではDecoderにおける基本処理、$(\mathrm{c})$ではmulti-level feature aggregationを用いたDecoderの処理の改良(SETR-MLA)についてそれぞれ図解されています。以下、それぞれについて詳しく確認を行います。
Transformerへの入力の用意
入力が$x \in \mathbb{R}^{H \times W \times 3}$のように得られるとき、ピクセル単位でTransformerの処理を行うとTransformerの系列の長さが$500 \times 500 \times 3 = 750{,}000$のように大変大きな値になります1。
そこでSETRではViTなどに同じく、$16 \times 16$ピクセルを$1$つのパッチと見なし、Linear Projectionなどを行うことで$x_{f} \in \mathbb{R}^{\frac{H}{16} \times \frac{W}{16} \times C}$のようなTransformerへの入力を作成します。
ここで行われているLinear Projection処理には「CvTで用いられる畳み込み」や「SegFormerで用いられるOverlapped Patch Merging」のような改良が考案されているので、合わせて確認しておくと良いと思います。
基本的なUpsamplingの概要
Transformerの出力のFeature mapが$\displaystyle Z^{L_{e}} \in \mathbb{R}^{\frac{HW}{256} \times C}$のように表されるとき、セグメンテーションを行うにあたってFeature mapを$\displaystyle Z’ \in \mathbb{R}^{\frac{H}{16} \times \frac{W}{16} \times C}$のような形式に変形を行います。
基本的な手法ではカテゴリ数を$K$とするとき$\displaystyle Z’ \in \mathbb{R}^{\frac{H}{16} \times \frac{W}{16} \times C}$を$\displaystyle \frac{H}{16} \times \frac{W}{16} \times K$に変形し、その後にUpsamplingを行いピクセル単位の分類を行います2。
Progressive Upsampling
前項のようにUpsamplingを一度に行う手法はノイズが多い予測となり得ることから、SETRでは段階的なアップサンプリング(PUP; Progressive UPsampling)が主に用いられます。
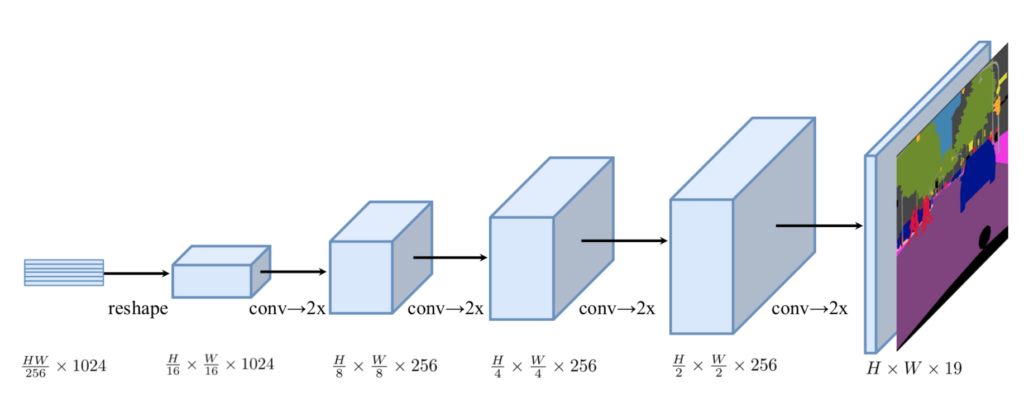
PUPでは上図のように$2$倍を$4$回行うことで$\displaystyle \frac{H}{16} \times \frac{W}{16}$を$H \times W$に変換します。このようなDecoderを用いる場合を、SETR論文ではSETR-PUPのように表します。
Multi-Level feature Aggregation
SETR論文ではFPN(Feature Pyramid Network)のように段階的に特徴マップを採用して用いるという手法も検討されています。
$$
\large
\begin{align}
\{ Z^{1}, Z^{2}, \cdots , Z^{L_e} \}
\end{align}
$$
上記のようにTransformerの各層のfeature mapが表される際に$M$個のレイヤーを用いて推論を行う場合、下記のように表されるレイヤーの集合$\{ Z^{m} \}$を用いてMulti-Level feature Aggregation(MLA)の処理が行われます。
$$
\large
\begin{align}
\{ Z^{m} \}, \quad m \in \left\{ \frac{L^{e}}{M}, 2 \frac{L^{e}}{M}, \cdots , M \frac{L^{e}}{M} \right\}
\end{align}
$$
たとえば$L_e=12, M=3$の時は$\{ Z^{3}, Z^{6}, Z^{9}, Z^{12} \}$を用いてMulti-Level feature Aggregationが行われます。このようにMLAに基づくDecoderを用いる場合を、SETR論文ではSETR-MLAのように表します。
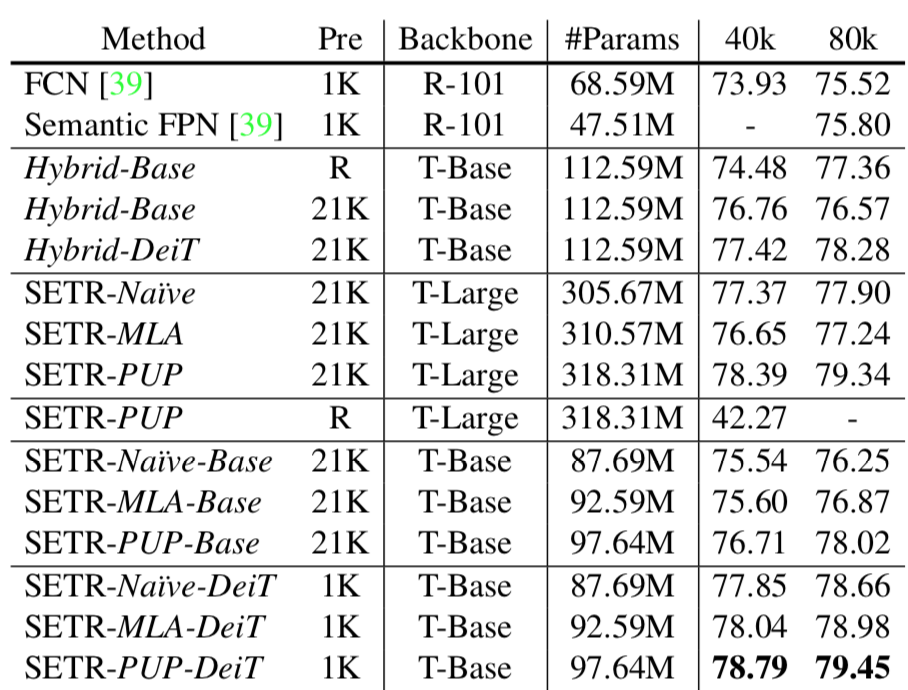
上記がSETR論文におけるパフォーマンスの表です。基本的にはSETR-PUPのパフォーマンスが良いことが確認できます。
SETR-MLAのパフォーマンスがそれほどよくない点についてはそもそもFPNの利点である「ダウンサンプリングによって解像度が低くなる前のfeature mapを反映させられる点」が実現できていないというのにあるのではないかと思います。
SETRが出たタイミングがViTと同時であるので、MLAの改良にあたってはその少し後に取り組まれた階層型のViTに基づく手法であるSegFormerに着目すると良いと思います。