
局所的な特徴量の抽出に適したCNNに対して、大域的な特徴量の抽出に適したTransformerはViT以降、多くのComputer Visionのタスクに用いられます。当記事ではTransformerを用いてシンプルかつ効率的なセグメンテーションを実現したSegFormerについて取りまとめました。
SegFormerの論文である「SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers」の内容を参考に作成を行いました。
・用語/公式解説
https://www.hello-statisticians.com/explain-terms
Contents
前提の確認
Transformerの概要
Dot Product Attentionに主に基づくTransformerの仕組みについては既知である前提で当記事はまとめました。下記などに解説コンテンツを作成しましたので、合わせて参照ください。
・直感的に理解するTransformerの仕組み(統計の森作成)
ViT
SegFormer
処理の概要
SegFormerの処理の全体は下図を元に掴むと良いです。
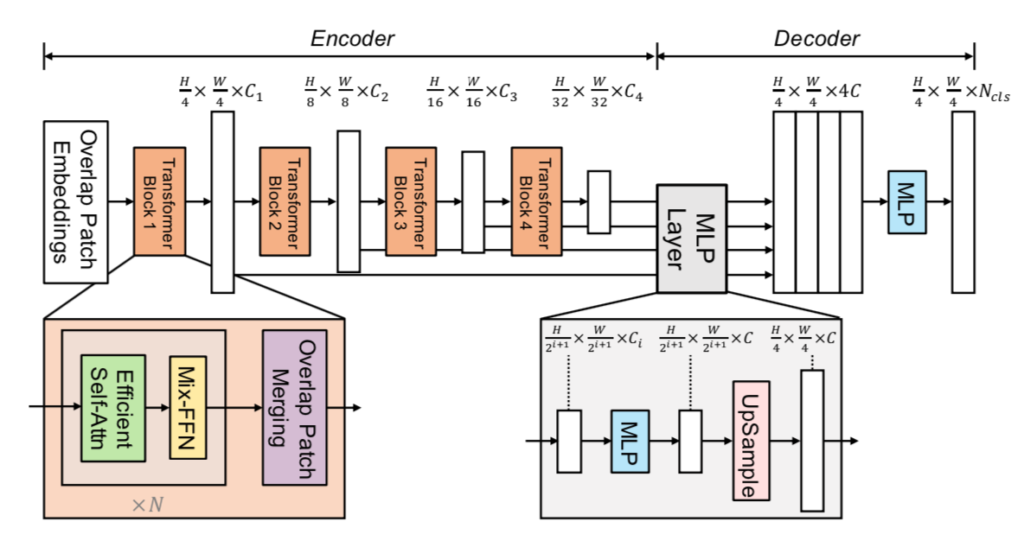
Hierarchical Feature Representation
$H \times W \times 3$の入力に対し、ステージ$i$におけるFeature mapを$F_{i}$とおくと、$F_{i}$のサイズは下記のように定義されます。
$$
\large
\begin{align}
F_{i} & \in \mathbb{R}^{\frac{H}{2^{i+1}} \times \frac{W}{2^{i+1}} \times C_i} \quad (1) \\
i &= \{ 1, 2, 3, 4 \}
\end{align}
$$
$i=1$のとき$2^{i+1}=2^{2}=4$、$i=2$のとき$2^{i+1}=2^{3}=8$なので、$(1)$式はSegFormer論文のFigure$\, 2$と対応することが確認できます。
また、$i$が大きくなるにつれて$C_i$は大きくなるので$C_{i} < C_{i+1}$が成立します。ここでの処理はVGGNetやResNetのbackboneネットワークによるFeature mapの作成と同様なものであると理解しておくと良いです。
Overlapped Patch Merging
パッチの特徴量の作成にあたっては、「パッチに含まれるピクセルや特徴量の値をそのまま用いる」というのが基本的である一方で、このようにパッチ特徴量の作成を行うと「パッチの境界における相関」をうまく取り扱うことができません1。
この解決にあたってSegFormerではOverlapped Patch Mergingが導入されます。Overlapped Patch Mergingはパッチ作成時にフィルタの大きなCNNを用い、パッチ作成にあたって用いる領域を重複させる手法です。
このようにOverlapped Patch Mergingを用いることでパッチ間の境界領域の相関も特徴量抽出にうまく反映させることができ、パフォーマンスの向上に役立ちます。
Efficient Self-Attention
Efficient Self-AttentionではPyramid Vision Transformer(PVT)のSpatial Reduction Attention(SRA)と同様の処理を行うことで、ViTのボトルネックである計算量の改良を実現します。
Fix-FFN
Mix-FFNでは下記のような式に基づいてFeed Forward Network(FFN)処理が行われます。
$$
\large
\begin{align}
X_{out} &= \mathrm{MLP}(\mathrm{GELU}(\mathrm{Conv}_{3 \times 3}(\mathrm{MLP}(X_{in})))) + X_{in} \\
\mathrm{GELU}(x) &= x \Phi(x) \\
\Phi(x) &= \int_{-\infty}^{x} \frac{1}{\sqrt{2 \pi}} \exp{ \left[ -\frac{t^{2}}{2} \right] } dt
\end{align}
$$
Mix-FFNでは上記の式に基づいて、$3 \times 3$の「Depth-wise Convolution」処理が途中で実行されます。また、Mix-FFNに畳み込み処理を導入することで位置情報を反映できるので、セグメンテーションタスクではPositional Encodingは必ずしも必要ではないとSegFormer論文に記載があります(We argue that positional encoding is actually not necessary for semantic segmentation.2)。
参考
・Transformer論文:Attention is All you need[$2017$]
・SegFormer論文
[…] 【CvT論文まとめ】畳み込みとMultiHead Attentionの対応 【SegFormer】Transformerを用いたシンプルかつ効率的なセグメンテーション […]
[…] Pyramid ViTとSpatial Reduction Attention 【SegFormer】Transformerを用いたシンプルかつ効率的なセグメンテーション […]