
DeepLearningの軽量化・高速化にあたって、畳み込み処理の分解などが行われることが多いです。当記事ではMobileNetsにおける点単位畳み込み(Pointwise Convolution)やチャネル別畳み込み(Channelwise Convolution)について取りまとめを行いました。当記事の作成にあたっては、MobileNets論文や「深層学習 第$2$版」の第$5$章「畳み込みニューラルネットワーク」の内容などを参考にしました。
・用語/公式解説
https://www.hello-statisticians.com/explain-terms
Contents
前提の確認
畳み込み演算の概要
畳み込み演算の数式
入力のチャネル数が$C$、フィルタの枚数$C_{out}$枚のとき畳み込みによって出力の$u_{ijk}$成分は下記のように計算されます。
$$
\large
\begin{align}
u_{ijk} = \sum_{c=1}^{C} \sum_{p=0}^{W_f-1} \sum_{q=0}^{H_f-1} x_{i+p,j+q,c} h_{pqck} + b_{k}
\end{align}
$$
詳しくは下記で取り扱いました。
MobileNetsの構成
Depthwise Separable Convolution概要
MobileNetsではDepthwise Separable Convolutionという畳み込みに基づいて構成されます。Depthwise Separable Convolutionは通常の$3 \times 3$の畳み込みを「空間方向」と「チャネル方向」に分解した処理であり、Depthwise Separable Convolutionを用いることでパラメータの軽量化や計算の高速化が可能になります。
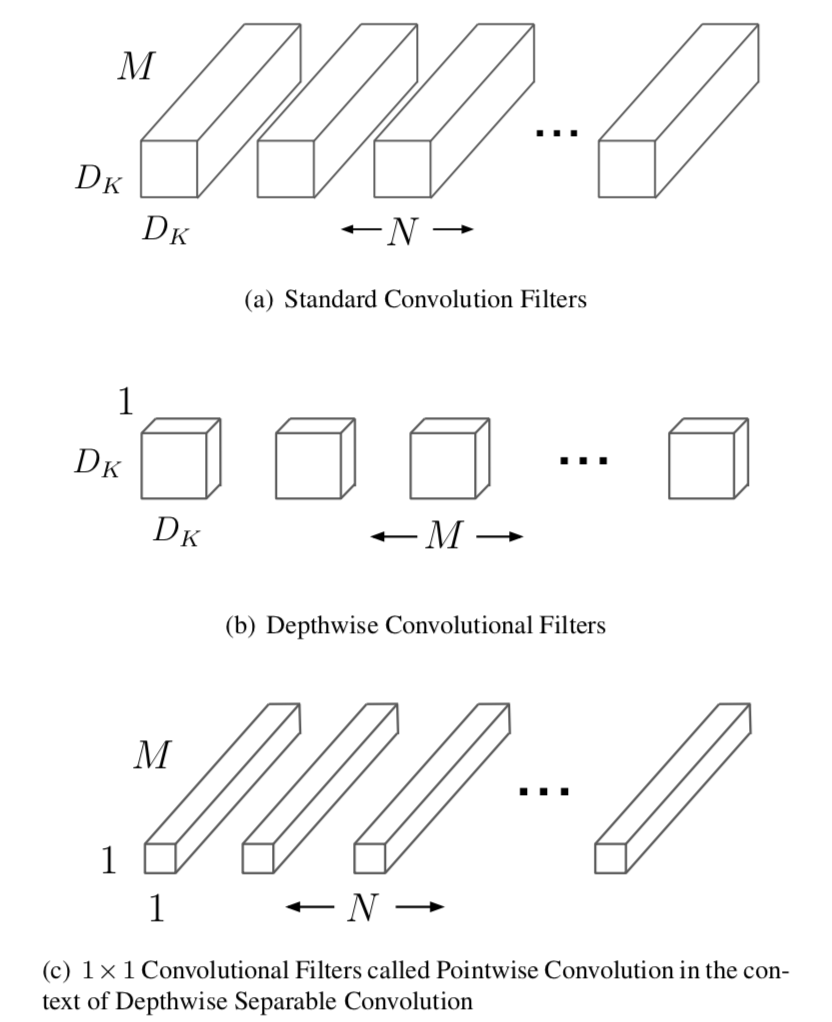
畳み込みの分解にあたっては上図などを元に理解すると良いです。$(a)$で表されたオーソドックスな$3 \times 3$の畳み込みを、チャネル毎に(channelwise/depthwise)畳み込みを行うのが$(b)$、位置毎に(pointwise)$1 \times 1$の畳み込みを行うのが$(c)$と解釈すれば良いです。$1 \times 1$は「VGGNet」や「ResNetのボトルネック構造」でも採用されていますが、MobileNetsではチャネル毎の畳み込みとセットで用いられている点が特徴的です。
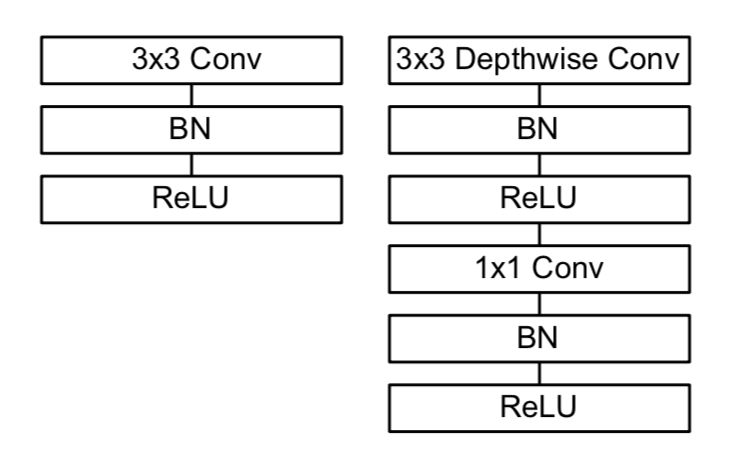
また、バッチ正規化(BN)や活性化関数(ReLU)も含めた処理の流れは上図のように表されます。左がオーソドックスな畳み込み、右がDepthwise Separable Convolutionにそれぞれ対応します。
Depthwise Separable Convolutionの数式
・チャネル別畳み込み(channelwise/depthwise convolution)
位置$(i,j)$のチャネル$c$におけるチャネル別畳み込みは下記のような数式で定義されます。
$$
\large
\begin{align}
u_{ijc} = \sum_{p=0}^{W_f-1} \sum_{q=0}^{H_f-1} z_{i+p,j+q,c}^{(l-1)} h_{pqc} + b_{c}
\end{align}
$$
上記のような式に基づいて、畳み込みの出力$u_{ijc}$が計算されます。$z$は中間層と$h$はフィルタ、$b$はバイアス項がそれぞれ対応します。
・位置別畳み込み(pointwise convolution)
位置$(i,j)$における位置別畳み込みは下記のような数式で定義されます。
$$
\large
\begin{align}
u_{ijc}’ = \sum_{c=1}^{C} u_{ijc} h_{c} + b_{c}
\end{align}
$$
計算コスト
フィルタのサイズが$W_{f} \times H_{f}$、入力のチャネルが$C$、出力のチャネルが$C_{out}$のとき、位置$(i,j)$における畳み込みの計算量について以下では確認を行います1。
・オーソドックスな畳み込みの積算の回数
$$
\large
\begin{align}
W_{f} \times H_{f} \times C \times C_{out}
\end{align}
$$
・Depthwise Separable Convolutionの積算の回数
$$
\large
\begin{align}
W_{f} \times H_{f} \times C + C \times C_{out}
\end{align}
$$
・(Depthwise Separable Convolutionの積算の回数)/(オーソドックスな畳み込みの積算の回数)
$$
\large
\begin{align}
\frac{W_{f} \times H_{f} \times C + C \times C_{out}}{W_{f} \times H_{f} \times C \times C_{out}} = \frac{1}{C_{out}} + \frac{1}{W_{f} H_{f}} \quad (1)
\end{align}
$$
$W_{f} = H_{f} = 3, \, C_{out}=128$のとき、$(1)$式は下記のように計算できます。
$$
\large
\begin{align}
\frac{1}{C_{out}} + \frac{1}{W_{f} H_{f}} &= \frac{1}{128} + \frac{1}{9} \\
&= 0.1189 \cdots
\end{align}
$$
MobileNetsの全体構成
MobileNets論文では下記のような$28$層構造でニューラルネットが構成されます。
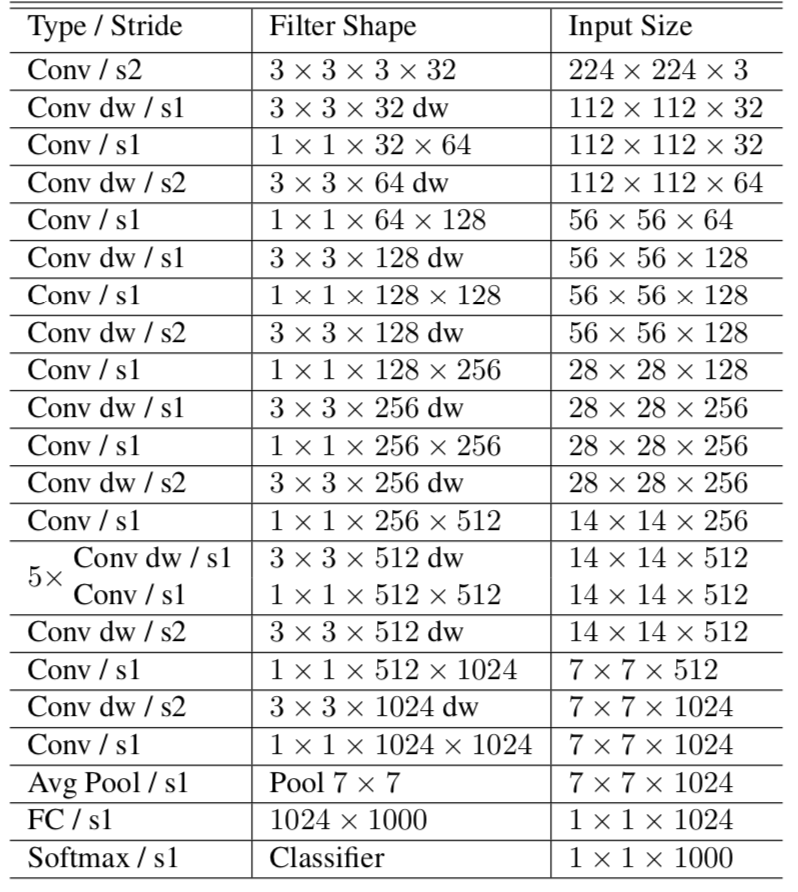
上記より、Conv層が$27$層、FC層が$1$層あることが確認できます2。基本的にはチャネル別畳み込みと位置別畳み込みが交互に行われると理解して良いと思います。
[…] Depthwise Separable ConvolutionとMobileNets […]