
下記などで取り扱った、乱数の生成に関する問題演習を通した理解ができるように問題・解答・解説をそれぞれ作成しました。
・標準演習$100$選
https://www.hello-statisticians.com/practice_100
Contents
基本問題
線形合同法・乗算型合同法
・問題
線形合同法(linear congruential method)は$1948$年頃にレーマー(Lehmer)が提案した手法で、仕組みがシンプルであるので乱数生成のイメージを掴むにあたって適した手法である。また、乗算型合同法は線形合同法の特殊な場合と考えられるので、両者は同時に理解することができる。
さて、線形合同法を理解するにあたっては、「整数に関する合同」と「数列の漸化式」の理解があれば十分であると思われる。以下の問題に答えよ。
i) $x_{n+1} = x_{n} + 2, x_1 = 1$のように表せるとき、$x_2, x_3$を求めよ。
ⅱ) $x_{n+1} = 2x_{n} + 1, x_1 = 1$のように表せるとき、$x_2, x_3$を求めよ。
ⅲ) 合同は「整数$x$を整数$M$で割った時の余りが等しいか」を表す概念である。このときの$M$を法(modulus)という。たとえば$2$と$5$は$3$で割った際にどちらも余りが$2$であるので、$3$を法とするとき合同であるといえる。このことは「$2 = 3 \quad (\mathrm{mod} \, 3)$」のように表すことができる。
上記に基づいて、法を$5$とするときに$2$と合同な自然数を$5$つ答えよ。
iv) $9$を法とするとき、$x_{n+1}=4x_{n}+2 \quad (\mathrm{mod} \, 9), x_1=1$に従って$x_2, x_3$を求めよ。
v) iv)の例の$x_4$以降を計算すると下記のようになる。
$$
\begin{align}
x_4=7, x_5=3, x_6=5, x_7=4, x_8=0, x_9=2, x_{10}=1, x_{11}=6, x_{12}=8
\end{align}
$$
上記には周期があると考えることができるが、どのような周期か答えよ。
・解答
i)
$x_2, x_3$は下記のように求めることができる。
$$
\begin{align}
x_2 &= x_{1} + 2 \\
&= 1 + 2 \\
&= 3 \\
x_3 &= x_{2} + 2 \\
&= 3 + 2 \\
&= 5
\end{align}
$$
ⅱ)
$x_2, x_3$は下記のように求めることができる。
$$
\begin{align}
x_2 &= 2x_{1} + 1 \\
&= 2 + 1 \\
&= 3 \\
x_3 &= 2x_{2} + 1 \\
&= 6 + 1 \\
&= 7
\end{align}
$$
ⅲ)
$$
\begin{align}
7, 12, 17, 22, 27
\end{align}
$$
iv)
$$
\begin{align}
x_2 &= 4x_{1} + 2 \\
&= 4 + 2 \\
&= 6 \\
x_3 &= 4x_{2} + 2 \\
&= 24 + 2 \\
&= 26 \\
&= 8 \quad (\mathrm{mod} \, 9)
\end{align}
$$
v)
$x_1$〜$x_9$と$x_{10}$〜$x_{18}$は一致し、これを周期とみなすことができる。線形合同法の計算の仕組み上、$1$度でも同じ値が出てくると以後の値は周期的に繰り返す。
・解説
線形合同法は「整数の合同」と「数列の漸化式」について理解していればそれほど難しくない手法だと思います。乗算合同法は線形合同法の定数項がないパターンであり、重複した値が得られやすい一方で計算コスト自体は低いため、合わせて抑えておくと良いと思います。
線形合同法、乗算型合同法の数式は下記でまとめたので、詳しくは下記も参照してみてください。
https://www.hello-statisticians.com/explain-terms-cat/random_sampling1.html
具体的な分布への逆関数法の適用
・問題
逆関数法は一様分布$\mathrm{Uniform}(0,1)$に基づく乱数を累積分布関数を持つ任意の確率分布と対応させることで確率分布に基づく乱数を生成させる手法である。逆関数の表記はやや分かりにくいので、下図に基づいて理解し立式や考察などを行うと良い。
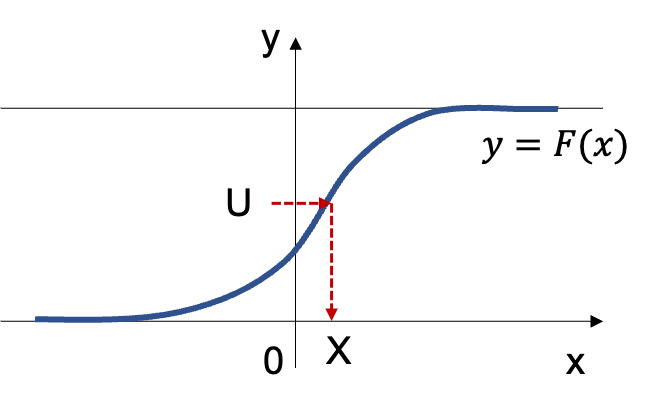
以下、逆関数法の具体的な分布への適用を確認するにあたって、「指数分布」、「ロジスティック分布」、「コーシー分布」に関してそれぞれ確認を行う。ここまでの内容を元に下記の問いにそれぞれ答えよ。
i) $\lambda>0$のとき、指数分布$\mathrm{Ex}(\lambda)$の確率密度関数$f_1(x)$と累積分布関数$F_1(x)$を表せ。
ⅱ) $U \sim \mathrm{Uniform}(0,1)$に基づいて乱数$U$が得られるとき、i)で表した指数分布の累積分布関数$F_1(x)$を用いて$X_1 \sim \mathrm{Ex}(\lambda)$となる乱数$X_1$を一様乱数$U$を用いて表せ。
ⅲ) ロジスティック回帰などに用いられるロジスティック分布の累積分布関数は$\displaystyle F_2(x) = \frac{1}{1+e^{-x}}$のように表すことができる。ⅱ)と同様にロジスティック分布に基づく乱数$X_2$を一様乱数$U$を用いて表せ。
iv) コーシー分布の確率密度関数と累積分布関数をそれぞれ$f_3(x), F_3(x)$とおくと、下記のように表せる。
$$
\large
\begin{align}
f_3(x) &= \frac{1}{\pi (1+x^2)} \\
F_3(x) &= \int_{-\infty}^{x} f_3(u) du \\
&= \int_{-\infty}^{x} \frac{1}{\pi (1+u^2)} du
\end{align}
$$
$u=\tan{\theta}$を用いて変数変換を行うことで累積分布関数$F_3(x)$に関して下記が成立することを示せ。
$$
\large
\begin{align}
F_3(x) = \frac{1}{2} + \frac{1}{\pi} \tan^{-1}{x}
\end{align}
$$
v) ⅱ)と同様にコーシー分布に基づく乱数$X_3$を一様乱数$U$を用いて表せ。
・解答
i)
指数分布$\mathrm{Ex}(\lambda)$の確率密度関数$f_1(x)$と累積分布関数$F_1(x)$は下記のように表せる。
$$
\large
\begin{align}
f_1(x) &= \lambda e^{-\lambda x}, \quad x \geq 0 \\
F_1(x) &= 1 – e^{-\lambda x}, \quad x \geq 0
\end{align}
$$
ⅱ)
乱数$X_1$に関して下記が成立する。
$$
\large
\begin{align}
U &= 1 – e^{-\lambda X_1} \\
e^{-\lambda X_1} &= 1-U \\
-\lambda X_1 &= \log{(1-U)} \\
X_1 &= – \frac{1}{\lambda} \log{(1-U)} \\
& \rightsquigarrow – \frac{1}{\lambda} \log{U}
\end{align}
$$
上記の記号の$\rightsquigarrow$は$1-U$と$U$のどちらで表しても意味合いが変わらないことを表すにあたって用いた。一般的な用法ではないので用いることの少ない記号を選定した。
ⅲ)
乱数$X_2$に関して下記が成立する。
$$
\large
\begin{align}
U &= \frac{1}{1+e^{-X_2}} \\
1+e^{-X_2} &= \frac{1}{U} \\
e^{-X_2} &= \frac{1-U}{U} \\
-X_2 &= \log{\frac{1-U}{U}} \\
X_2 &= -\log{\frac{1-U}{U}} \\
&= \log{\frac{U}{1-U}}
\end{align}
$$
iv)
$u=\tan{\theta}$を用いて変数変換を行うことで累積分布関数$F_3(x)$は下記のように変形できる。
$$
\large
\begin{align}
F_3(x) &= \int_{-\infty}^{x} \frac{1}{\pi (1+u^2)} du \\
&= \frac{1}{2} + \int_{0}^{x} \frac{1}{\pi (1+u^2)} du \\
&= \frac{1}{2} + \int_{0}^{\tan^{-1}{x}} \frac{1}{\pi (1+\tan{\theta})} \cdot \frac{1}{\cos^{2}{\theta}} d \theta \\
&= \frac{1}{2} + \int_{0}^{\tan^{-1}{x}} \frac{\cancel{\cos^{2}{\theta}}}{\pi \cancel{\cos^{2}{\theta}}} d \theta \\
&= \frac{1}{2} + \left[ \frac{1}{\pi} \theta \right]_{0}^{\tan^{-1}{x}} \\
&= \frac{1}{2} + \frac{1}{\pi} \tan^{-1}{x}
\end{align}
$$
v)
乱数$X_3$に関して下記が成立する。
$$
\large
\begin{align}
U &= \frac{1}{2} + \frac{1}{\pi} \tan^{-1}{X_3} \\
\tan^{-1}{X_3} &= \pi \left( U – \frac{1}{2} \right) \\
X_3 &= \tan{ \left[ \left( U – \frac{1}{2} \right) \pi \right] }
\end{align}
$$
・解説
下記などを元に作成を行いました。
M系列とビット演算
・問題
「線形合同法・乗算型合同法」は多次元の一様分布の生成を行う際に適切な乱数が得られない「多次元疎結晶構造」を生じる。よって、実用的にはM系列という考え方に基づく一様乱数が用いられることが多く、現在多く使われるメルセンヌ・ツイスタ法もM系列に基づいた手法である。
この問題では以下、M系列に基づく乱数生成の手法について演習形式で確認を行う。下記の問いにそれぞれ答えよ。
i) M系列では$2$で割った余りに基づく$\mathrm{mod} \, 2$を元に乱数の生成を行う。$3=1 \, (\mathrm{mod} \, 2)$のような表記に基づいて、$2,5,8$を表せ。
ⅱ) 線形合同法や乗算型合同法では$x_n$に基づいて$x_{n+1}$の生成を行ったが、M系列では下記のような漸化式を用いる
$$
\begin{align}
x_{n+p} &= x_{n+q} + x_{n} \, (\mathrm{mod} \, 2) \quad \cdots \, (1) \\
p & > q
\end{align}
$$
$p=5, q=2$、$x_0=1, x_1=1, x_2=0, x_3=0, x_4=1$のとき、$x_5, x_6, x_7, x_8, x_9$をそれぞれ計算せよ。
ⅲ) $x_{n+q} \in \{ 0,1 \} , x_{n} \in \{ 0,1 \}$のとき、排他的論理和の$\oplus$を用いて$(1)$式は下記のように表せる。
$$
\begin{align}
x_{n+p} &= x_{n+q} \oplus x_{n} \\
p & > q
\end{align}
$$
$\oplus$の定義に基づいて$0 \oplus 0, 1 \oplus 0, 1 \oplus 1$をそれぞれ計算せよ。
iv) ⅱ)で得られた$x_0$〜$x_9$を$2$つずつ$X_0=11_{(2)}, X_1=00_{(2)}, X_2=11_{(2)}, X_3=11_{(2)}, X_4=10_{(2)}$で表す。ここで$(2)$は$2$進数表記であることを表すにあたって用いた。$X_0$〜$X_4$をそれぞれ$10$進数表記で表せ。
v) $X_n$に関して下記のような演算を定める。
$$
\begin{align}
X_{n+5} &= X_{n+2} \oplus X_{n}
\end{align}
$$
上記の$\oplus$は桁毎に排他的論理和を定義したと考えるとき、プログラムなどを元に$X_{100}$まで生成し、$0$〜$3$が概ね均等に得られることを確認せよ。
・解答
i)
$2,5,8$は$\mathrm{mod} \, 2$に基づいて下記のように表すことができる。
$$
\begin{align}
2 &= 0 \, (\mathrm{mod} \, 2) \\
5 &= 1 \, (\mathrm{mod} \, 2) \\
8 &= 0 \, (\mathrm{mod} \, 2)
\end{align}
$$
ⅱ)
$x_5, x_6, x_7, x_8, x_9$はそれぞれ下記のように計算できる。
$$
\large
\begin{align}
x_5 &= x_2 + x_0 = 0 + 1 = 1 \, (\mathrm{mod} \, 2) \\
x_6 &= x_3 + x_1 = 0 + 1 = 1 \, (\mathrm{mod} \, 2) \\
x_7 &= x_4 + x_2 = 1 + 0 = 1 \, (\mathrm{mod} \, 2) \\
x_8 &= x_5 + x_3 = 1 + 0 = 1 \, (\mathrm{mod} \, 2) \\
x_9 &= x_6 + x_4 = 1 + 1 = 0 \, (\mathrm{mod} \, 2)
\end{align}
$$
ⅲ)
$\oplus$の定義に基づいて$0 \oplus 0, 1 \oplus 0, 1 \oplus 1$は下記のように計算できる。
$$
\large
\begin{align}
0 \oplus 0 &= 0 \\
1 \oplus 0 &= 1 \\
1 \oplus 1 &= 0
\end{align}
$$
iv)
$X_0$〜$X_4$はそれぞれ下記のように表せる。
$$
\large
\begin{align}
X_0 &= 11_{(2)} = 1 \cdot 2^{1} + 1 \cdot 2^{0} = 3 \\
X_1=00_{(2)} = 0 \cdot 2^{1} + 0 \cdot 2^{0} = 0 \\
X_2=11_{(2)} = 1 \cdot 2^{1} + 1 \cdot 2^{0} = 3 \\
X_3=11_{(2)} = 1 \cdot 2^{1} + 1 \cdot 2^{0} = 3 \\
X_4=10_{(2)} = 1 \cdot 2^{1} + 0 \cdot 2^{0} = 2
\end{align}
$$
v)
下記を実行することで確認できる。
import numpy as np
import matplotlib.pyplot as plt
p, q = 5, 2
X = np.zeros(100+1)
X[:5] = np.array([3., 0., 3., 3., 2.])
for i in range(X.shape[0]-5):
X[i+p] = int(X[i+q]) ^ int(X[i])
plt.hist(X)
plt.show()実行結果
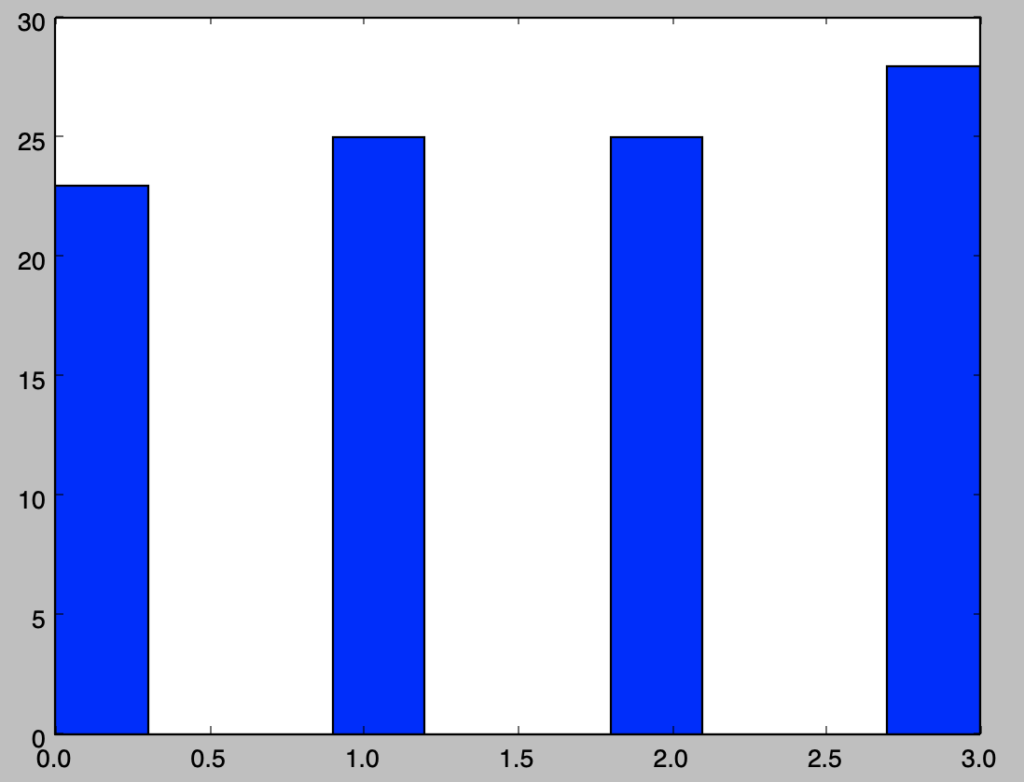
・解説
M系列は当問題で取り扱ったように$\mathrm{mod} \, 2$に基づいてビット演算を行うことで乱数の生成を行う手法です。M系列の詳細や近年よく用いられるメルセンヌ・ツイスタ法に関しては下記で詳しく取りまとめを行いました。
発展問題
モンテカルロ積分
・問題
モンテカルロ積分は乱数を用いて定積分の値を推定する手法であり、乱数を用いて数値計算を行う手法のモンテカルロ法の一種である。以下の問いにそれぞれ答えよ。
i) 関数$g(x)$に関する定積分$\displaystyle \theta = \int_{0}^{1} g(x) dx$の推定を行うことを考える。$X \sim \mathrm{Uniform}(0,1)$のとき$E[X]=1/2, E[g(X)]=\theta$であることを示せ。
ⅱ) i)より定積分$\displaystyle \theta = \int_{0}^{1} g(x) dx$の推定にあたっては$E[g(X)]$の推定を行えばよいと考えられる。$X \sim \mathrm{Uniform}(0,1)$に基づいて標本$x_1, x_2, \cdots x_n$が得られるとき標本を用いて$E[X]$の推定値を表せ。
ⅲ) ⅱ)の結果は大数の弱法則を考えることで$E[X]$に収束する。同様に考えることで$\theta=E[g(X)]$の推定量$\hat{\theta}$を$X_i \sim \mathrm{Uniform}(0,1)$を用いて表せ。
iv) ⅲ)の式に基づいてPythonなどのプログラムを用いて関数$g(x)=e^{-x}$について$\hat{\theta}$の推定値を計算を行い、$1-e^{-1}$に近い値が得られることを確認せよ。
v) $\displaystyle I = \int_{2}^{5} g(x) dx$の推定手順を示し、iv)と同様にプログラムなどを用いて推定値を計算せよ。
・解答
i)
一様分布$\mathrm{Uniform}(0,1)$の確率密度関数を$f(x)$とおくと、$E[X]$は下記のように表せる。
$$
\large
\begin{align}
E[X] &= \int_{0}^{1} x \cdot 1 dx \\
&= \left[ \frac{1}{2}x^2 \right]_{0}^{1} \\
&= \frac{1}{2}
\end{align}
$$
同様に$E[g(X)]$は下記のように表せる。
$$
\large
\begin{align}
E[g(X)] &= \int_{0}^{1} g(x) \cdot 1 dx \\
&= \int_{0}^{1} g(x) dx = \theta
\end{align}
$$
ⅱ)
$E[X]$の推定値は下記のように標本平均によって表される。
$$
\large
\begin{align}
\bar{x} = \frac{1}{n} \sum_{i=1}^{n} x_i
\end{align}
$$
ⅲ)
$\hat{\theta}$は下記のように表せる。
$$
\large
\begin{align}
\hat{\theta} = \frac{1}{n} \sum_{i=1}^{n} g(X_i)
\end{align}
$$
iv)
import numpy as np
np.random.seed(0)
X = np.random.rand(10000)
g_X = np.e**(-X)
g_x = 1-np.e**(-1)
print("Estimated E[g(X)]: {:.3f}".format(np.mean(g_X)))
print("E[g(X)]: {:.3f}".format(np.mean(g_x)))実行結果
Estimated E[g(X)]: 0.634
E[g(X)]: 0.632上記より類似の結果が得られたことが確認できる。
v)
一様分布$\mathrm{Uniform}(2,5)$に基づいて生成した乱数を元にモンテカルロ積分を行うと考えればよい。$\mathrm{Uniform}(2,5)$の確率密度関数が$f(x)=1/3, \, 2 \leq x \leq 5$であることからi)と同様に考えることで$E[g(X)]$は下記のように表せる。
$$
\large
\begin{align}
E[g(X)] &= \int_{2}^{5} g(x) \cdot \frac{1}{3} dx \\
&= \frac{1}{3} \int_{2}^{5} g(x) dx = \frac{1}{3} I
\end{align}
$$
よって$\mathrm{Uniform}(2,5)$に基づいて生成された$x_1, \cdots , x_n$元にを$\displaystyle 3 \sum_{i=1}^{n} g(x_i)$を計算することで推定を行うことができる。
import numpy as np
np.random.seed(0)
X = 3.*np.random.rand(10000)+2.
g_X = 3.*np.e**(-X)
g_x = np.e**(-2)-np.e**(-5)
print("Estimated E[g(X)]: {:.3f}".format(np.mean(g_X)))
print("E[g(X)]: {:.3f}".format(np.mean(g_x)))実行結果
Estimated E[g(X)]: 0.130
E[g(X)]: 0.129・解説
下記などを参考に作成を行いました。
ボックス・ミュラー法の導出と正規分布に従う乱数の生成
・問題
一様分布に従う乱数が得られる前提で正規分布に従う乱数の生成を行うにあたっては主に「中心極限定理」を用いる手法と「ボックス・ミュラー法」を用いる手法がある。中心極限定理に基づく手法は複数の乱数の平均が中心極限定理に基づいて正規分布に従うことに基づく手法であるが、$1$つのサンプルを作成するにあたって$n=12$個がよく用いられるなどあまり効率的ではない。よって以下では「正規分布に従う乱数の生成」にあたって実用的に用いられることの多い「ボックス・ミュラー法」の原理に関して確認を行う。
一様乱数$U_1 \sim \mathrm{Uniform}(0,1), U_2 \sim \mathrm{Uniform}(0,1)$に対し、下記の変換によって得られる$X, Y$は互いに独立に標準正規分布$\mathcal{N}(0,1)$に従う。
$$
\begin{align}
X &= \sqrt{-2 \log{U_{1}}} \cdot \cos{(2 \pi U_{2})} \\
Y &= \sqrt{-2 \log{U_{1}}} \cdot \sin{(2 \pi U_{2})}
\end{align}
$$
上記に基づいて乱数を生成する手法を「ボックス・ミュラー法」という。ここまでの内容を元に下記の問いに答えよ。
i) 関数電卓やPythonなどを用いて$(U_1,U_2) = (0.1,0.3), (0.8,0.6), (0.2,0.9)$に対応する$(X,Y)$の数値の計算を行え。
ⅱ) 確率変数$X, Y$が$X \sim \mathcal{N}(0,1), Y \sim \mathcal{N}(0,1)$であるとき、確率エレメント$P(x \leq X \leq x+dx, y \leq Y \leq y+dy)$は下記のように表せる。
$$
\large
\begin{align}
& P(x \leq X \leq x+dx, y \leq Y \leq y+dy) \\
&= f(x,y)dxdy = f(x)f(y)dxdy \\
&= \frac{1}{\sqrt{2 \pi}} e^{-\frac{x^2}{2}} \cdot \frac{1}{\sqrt{2 \pi}} e^{-\frac{y^2}{2}} dx dy \quad (1)
\end{align}
$$
$(1)$式に対し、$x = r \cos{\theta}, y = r \sin{\theta}$のような変数変換を考えるとき、変数変換のヤコビ行列式$J(R,\Theta)$を計算せよ。
ⅲ) $(1)$式に対し、$x = r \cos{\theta}, y = r \sin{\theta}$を用いて変数変換を行え。
iv) ⅲ)の導出結果に対して$s=r^2$のような変数変換を行い、下記を導出せよ。
$$
\large
\begin{align}
f(x,y)dxdy &= \frac{1}{\sqrt{2 \pi}} e^{-\frac{x^2}{2}} \cdot \frac{1}{\sqrt{2 \pi}} e^{-\frac{y^2}{2}} dx dy \quad (1) \\
&= \frac{1}{2 \pi} d \theta \frac{1}{2} e^{-\frac{s}{2}} ds \quad (2)
\end{align}
$$
v) $(2)$式の$\displaystyle \frac{1}{2 \pi}$は一様分布$\mathrm{Uniform}(0,2 \pi)$の確率密度関数に対応する。乱数$\Theta \sim \mathrm{Uniform}(0,2 \pi)$を一様乱数$U_2 \sim \mathrm{Uniform}(0,1)$を元に得る方法を答えよ。
vi) $(2)$式の$\displaystyle \frac{1}{2} e^{-\frac{s}{2}}$は指数分布$\displaystyle \mathrm{Ex} \left( \frac{1}{2} \right)$の確率密度関数に対応する。指数分布$\mathrm{Ex}(\lambda)$の累積分布関数が$F(x)=1-e^{-\lambda x}$であることを元に、逆関数法を用いて乱数$\displaystyle R^2 \sim \mathrm{Ex} \left( \frac{1}{2} \right)$を一様乱数$U_1 \sim \mathrm{Uniform}(0,1)$を元に得る方法を答えよ。
vⅱ)
v)、vi)の結果を元にボックス・ミュラー法の乱数生成が下記で得られることを確認せよ。
$$
\large
\begin{align}
X &= R \cos{\Theta} = \sqrt{-2 \log{U_{1}}} \cdot \cos{(2 \pi U_{2})} \\
Y &= R \sin{\Theta} = \sqrt{-2 \log{U_{1}}} \cdot \sin{(2 \pi U_{2})}
\end{align}
$$
・解答
i)
下記を実行することでそれぞれ計算を行うことができる。
import numpy as np
U_1, U_2 = np.array([0.1, 0.8, 0.2]), np.array([0.3, 0.6, 0.9])
X = np.sqrt(-2*np.log(U_1)) * np.cos(2*np.pi*U_2)
Y = np.sqrt(-2*np.log(U_1)) * np.sin(2*np.pi*U_2)
print(X)
print(Y)・実行結果
> print(X)
[-0.66313997 -0.54046156 1.45147566]
> print(Y)
[ 2.04093497 -0.39266831 -1.05455879]ⅱ)
変数変換のヤコビ行列式$J(R,\Theta)$は下記のように計算できる。
$$
\large
\begin{align}
J(R,\theta) &= \left| \begin{array}{cc} \frac{\partial x}{\partial r} & \frac{\partial x}{\partial \theta} \\ \frac{\partial y}{\partial r} & \frac{\partial y}{\partial \theta} \end{array} \right| \\
&= \left| \begin{array}{cc} \cos{\theta} & -r \sin{\theta} \\ \sin{\theta} & r \cos{\theta} \end{array} \right| \\
&= r \cos^{2}{\theta} + r \sin^{2}{\theta} = r
\end{align}
$$
ⅲ)
$(3)$式に対して下記のような変数変換を行うことができる。
$$
\large
\begin{align}
f(x,y)dxdy &= \frac{1}{\sqrt{2 \pi}} e^{-\frac{x^2}{2}} \cdot \frac{1}{\sqrt{2 \pi}} e^{-\frac{y^2}{2}} dx dy \quad (3) \\
&= \frac{1}{\sqrt{2 \pi}} e^{-\frac{r^2 \cos^{2}{\theta}}{2}} \cdot \frac{1}{\sqrt{2 \pi}} e^{-\frac{r^2 \sin^{2}{\theta}}{2}} J(R,\theta) dr d \theta \\
&= \frac{1}{2 \pi} r e^{-\frac{r^2}{2}} dr d \theta
\end{align}
$$
iv)
$\displaystyle r dr = \frac{1}{2} ds$より、$s=r^2$を元に下記のような変数変換を行える。
$$
\large
\begin{align}
f(x,y)dxdy &= \frac{1}{2 \pi} r e^{-\frac{r^2}{2}} dr d \theta \\
&= \frac{1}{2 \pi} e^{-\frac{s}{2}} \cdot \frac{1}{2} ds d \theta \\
&= \frac{1}{2 \pi} d \theta \frac{1}{2} e^{-\frac{s}{2}} ds
\end{align}
$$
v)
$\Theta = 2 \pi U_2$を計算すれば良い。
vi)
累積分布関数に$\displaystyle \lambda=\frac{1}{2}$を代入することで$F(x)=1-e^{-\frac{x}{2}}$が得られる。ここで逆関数法を用いるにあたっては、$\displaystyle U_1=F(x)=1-e^{-\frac{R^2}{2}}$を$R$について解けば良い。
$$
\large
\begin{align}
U_1 &= F(x)=1-e^{-\frac{R^2}{2}} \\
e^{-\frac{R^2}{2}} &= 1-U_1 \\
-\frac{R^2}{2} &= \log{(1-U_1)} \\
R^2 &= -2 \log{(1-U_1)} \\
R &= \sqrt{-2 \log{(1-U_1)}}
\end{align}
$$
vⅱ)
$r$と$\theta$に対応する乱数$R, \Theta$が得られれば、変換式$x = r \cos{\theta}, y = r \sin{\theta}$に基づいて標準正規分布に基づく乱数$X, Y$が下記のように得られる。
$$
\large
\begin{align}
X &= R \cos{\Theta} = \sqrt{-2 \log{(1-U_{1})}} \cdot \cos{(2 \pi U_{2})} \\
Y &= R \sin{\Theta} = \sqrt{-2 \log{(1-U_{1})}} \cdot \sin{(2 \pi U_{2})}
\end{align}
$$
ここで$U_1 \sim \mathrm{Uniform}(0,1)$であることから、上記の式の$1-U_1$を$U_1$で置き換えても式の意味は同じである。よって、下記のようなボックス・ミュラー法の式が得られる。
$$
\large
\begin{align}
X &= R \cos{\Theta} = \sqrt{-2 \log{U_{1}}} \cdot \cos{(2 \pi U_{2})} \\
Y &= R \sin{\Theta} = \sqrt{-2 \log{U_{1}}} \cdot \sin{(2 \pi U_{2})}
\end{align}
$$
・解説
下記の導出を元に作成を行いました。正規分布に基づく乱数は応用先が多い一方で、変数変換$2$回と指数分布への逆関数法の適用など導出がやや複雑なので、何度か演習を行なっておくと良いと思います。
ガンマ分布の形状パラメータ$\alpha$が整数の場合のサンプリング
・問題
ガンマ分布の形状パラメータ$\alpha$が整数の場合は「指数分布に基づく乱数生成」と「ガンマ分布の再生性」の$2$点を元にサンプリングを行うことができる。以下ではこの導出に関して演習形式で取り扱う。
まず前問の「ボックス・ミュラー法の導出と正規分布に従う乱数の生成」より、$Y \sim \mathrm{Ex}(\lambda)$に基づく乱数$Y$は$U \sim \mathrm{Uniform}(0,1)$である一様乱数$U$を用いて下記のように生成できる。
$$
\large
\begin{align}
Y = -\frac{1}{\lambda} \log{U}
\end{align}
$$
上記の指数分布$\mathrm{Ex}(\lambda)$はガンマ分布$\displaystyle \mathrm{Ga} \left( 1,\frac{1}{\lambda} \right)$に一致するので、ガンマ分布$\mathrm{Ga}(1,\beta)$に基づく乱数$X$は下記のように生成できる。
$$
\large
\begin{align}
X = -\beta \log{U} \quad (1)
\end{align}
$$
上記に対し、ガンマ分布の再生性を適用することで、形状パラメータ$\alpha$が整数の場合のガンマ分布の生成を行うことができる。ここまでの内容を元に以下の問いに答えよ。
i) ガンマ分布$\mathrm{Ga} (\alpha,\beta)$の確率密度関数$f(x)$を$x,\alpha,\beta$などを用いて表せ。また、$\alpha=1,\beta=1/\lambda$を代入すると指数分布$\mathrm{Ex}(\lambda)$の確率密度関数に一致することを確かめよ。
ⅱ) ガンマ分布$\mathrm{Ga} (\alpha,\beta)$のモーメント母関数を$m(t)=E[e^{tX}]$とおくとき、$m(t)$を導出せよ。
ⅲ) ⅱ)で導出を行なったモーメント母関数を元にガンマ分布の再生性を示せ。
iv) ⅲ)で示したガンマ分布の再生性を元に、下記が成立する。
$$
\begin{align}
X_1 + X_2 + \cdots X_n \sim \mathrm{Ga}(n,\beta)
\end{align}
$$
$(1)$式に基づいて一様乱数を用いて$\mathrm{Ga}(n,\beta)$に従う乱数$\displaystyle Z = \sum_{i=1}^{n} X_i$を生成する式を答えよ。
v) iv)の結果をガンマ分布の確率密度関数の形状やガンマ分布$\mathrm{Ga}(\alpha,\beta)$の平均が$\alpha \beta$であることなどに基づいて簡単に解釈せよ。
・解答
i)
ガンマ分布$\mathrm{Ga} (\alpha,\beta)$の確率密度関数$f(x)$は下記のように表せる。
$$
\large
\begin{align}
f(x) = \frac{1}{\beta^{\alpha} \Gamma(\alpha)} x^{\alpha-1} \exp{\left( -\frac{x}{\beta} \right)}
\end{align}
$$
上記に$\alpha=1, \beta=1/\lambda$を代入すると$\Gamma(\alpha)=1$より下記のように変形できる。
$$
\large
\begin{align}
f(x) &= \frac{1}{\beta^{\alpha} \Gamma(\alpha)} x^{\alpha-1} \exp{\left( -\frac{x}{\beta} \right)} \\
&= \frac{1}{(1/\lambda)^{1} \Gamma(1)} x^{1-1} \exp{\left( -\frac{x}{1/\lambda} \right)} \\
&= \lambda e^{-\lambda x}
\end{align}
$$
上記は指数分布$\mathrm{Ex}(\lambda)$の確率密度関数に一致する。
ⅱ)
ガンマ分布$\mathrm{Ga} (\alpha,\beta)$のモーメント母関数$m(t)=E[e^{tX}]$は下記のように導出できる。
$$
\large
\begin{align}
m(t) &= E[e^{tX}] = \int_{0}^{\infty} e^{tx} f(x) dx \\
&= \int_{0}^{\infty} \exp{(tx)} \times \frac{1}{\beta^{\alpha} \Gamma(\alpha)} x^{\alpha-1} \exp{\left( -\frac{x}{\beta} \right)} dx \\
&= \int_{0}^{\infty} \frac{1}{\beta^{\alpha} \Gamma(\alpha)} x^{\alpha-1} \exp{\left( -\frac{x}{\beta} + t \beta \right)} dx \\
&= \int_{0}^{\infty} \frac{1}{\beta^{\alpha} \Gamma(\alpha)} x^{\alpha-1} \exp{\left( -\frac{x}{\beta/(1 – t \beta)} \right)} dx \\
&= \frac{1}{(1 – t \beta)^{\alpha}} \int_{0}^{\infty} \frac{(1 – t \beta)^{\alpha}}{\beta^{\alpha} \Gamma(\alpha)} x^{\alpha-1} \exp{\left( -\frac{x}{\beta/(1 – t \beta)} \right)} dx \\
&= \frac{1}{(1 – t \beta)^{\alpha}} \times 1 = \frac{1}{(1-t \beta)^{\alpha}}
\end{align}
$$
ⅲ)
$X_1 \sim \mathrm{Ga} (\alpha_1,\beta), X_2 \sim \mathrm{Ga} (\alpha_2,\beta)$のとき、$m_{X_1+X_2}(t) = E[e^{t(X_1+X_2)}]$は下記のように計算できる。
$$
\large
\begin{align}
m_{X_1+X_2}(t) &= E[e^{t(X_1+X_2)}] = E[e^{tX_1}] E[e^{tX_2}] \\
&= \frac{1}{(1-t \beta)^{\alpha_1}} \times \frac{1}{(1-t \beta)^{\alpha_2}} \\
&= \frac{1}{(1-t \beta)^{\alpha_1+\alpha_2}}
\end{align}
$$
モーメント母関数と確率分布の$1$対$1$対応より、$X_1+X_2 \sim \mathrm{Ga} (\alpha_1+\alpha_2,\beta)$が成立するのでガンマ分布の再生性が示される。
iv)
$U_1, U_2, \cdots U_n \sim \mathrm{Uniform}(0,1), \, \mathrm{i.i.d.,}$のとき、$\mathrm{Ga}(n,\beta)$に従う乱数$\displaystyle Z = \sum_{i=1}^{n} X_i$は下記の式により生成できる。
$$
\large
\begin{align}
\sum_{i=1}^{n} X_i &= -\sum_{i=1}^{n} \beta\log{U_i} \\
&= -\beta \log{ \left[ \prod_{i=1}^{n} U_i \right] }
\end{align}
$$
v)
import math
import numpy as np
import matplotlib.pyplot as plt
alpha = np.array([2., 3., 5., 7., 10.])
beta = 1.
x = np.arange(0., 15.1, 0.1)
for i in range(alpha.shape[0]):
f_x = x**(alpha[i]-1) * np.e**(-x/beta) /(beta**alpha[i] * math.factorial(alpha[i]-1))
plt.plot(x,f_x,label="alpha: {}, beta: {}".format(alpha[i],beta))
plt.legend()
plt.show()実行結果
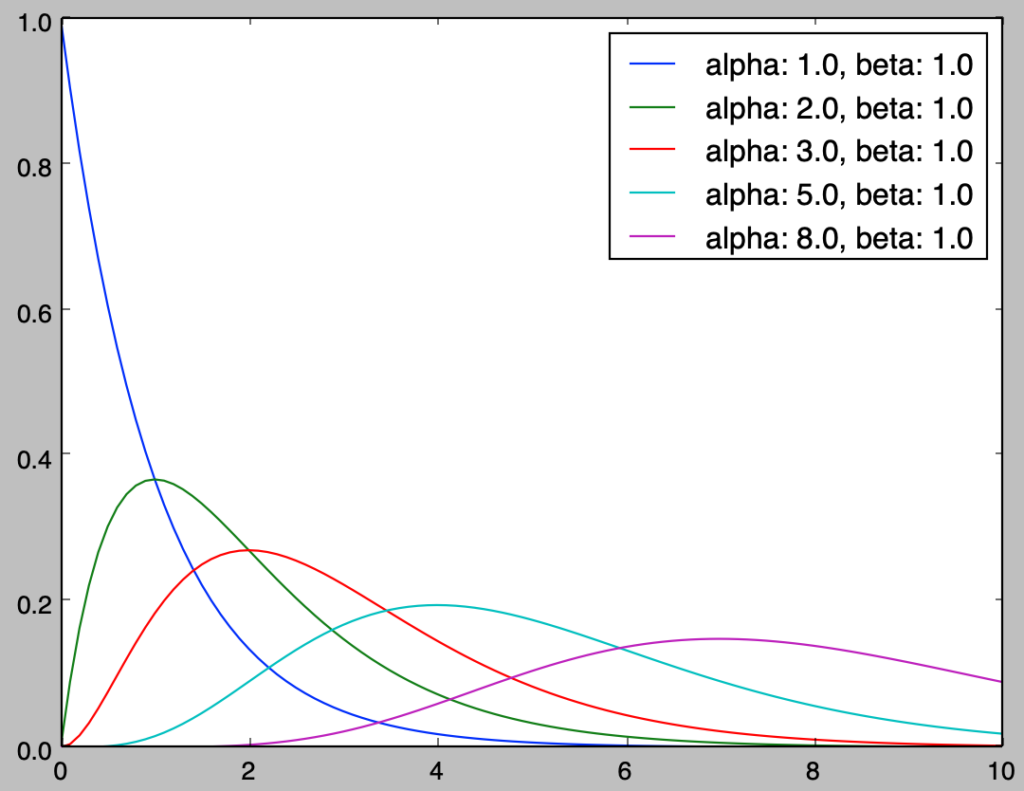
上図の青の確率密度関数に基づいて生成される乱数の和によってその他のガンマ分布の乱数が生成されると直感的に解釈することができる。ガンマ分布$\mathrm{Ga}(\alpha,\beta)$の平均は$\alpha \beta$であることに基づいても同様の解釈ができる。
・解説
下記などに基づいて問題の作成を行いました。
ガンマ分布の形状パラメータ$\alpha$が$($整数$+1/2)$の場合のサンプリング
・問題
前問の「ガンマ分布の形状パラメータ$\alpha$が整数の場合のサンプリング」より、ガンマ分布の形状パラメータ$\alpha$が整数の場合は一様乱数$U_1, U_2, \cdots U_n \sim \mathrm{Uniform}(0,1), \, \mathrm{i.i.d.,}$を用いることで、$\mathrm{Ga}(n,\beta)$に従う乱数$\displaystyle \sum_{i=1}^{n} X_i$を下記のように生成できる。
$$
\large
\begin{align}
\sum_{i=1}^{n} X_i &= -\sum_{i=1}^{n} \beta\log{U_i} \\
&= -\beta \log{ \left[ \prod_{i=1}^{n} U_i \right] }
\end{align}
$$
この問題では以下、形状パラメータ$\alpha$が整数でない場合への拡張にあたって$($整数$+1/2)$の取り扱いに関して演習形式で確認を行う。以下の問いにそれぞれ答えよ。
i) ガンマ分布$\mathrm{Ga}(\alpha,\beta)$の確率密度関数を$f(x)$とおくと$f(x)$は下記のように表すことができる。
$$
\begin{align}
f(x) = \frac{1}{\beta^{\alpha} \Gamma(\alpha)} x^{\alpha-1} \exp{\left( -\frac{x}{\beta} \right)}
\end{align}
$$
上記を元に$\mathrm{Ga}(1/2,2)$の確率密度関数$f_1(x)$と$\mathrm{Ga}(1/2,\beta)$の確率密度関数$f_2(y)$をそれぞれ答えよ。
ⅱ) i)で確認した$f_1(x), f_2(y)$の$\exp$の項に着目し、$x$から$y$の変数変換の式を作成せよ。
ⅲ) ⅱ)の式を元に$f_1(x)$の変数変換を行い、$f_2(y)$を導出せよ。
iv) $f_1(x)$は自由度$1$の$\chi^2$分布$\chi^2(1)$の確率密度関数であるので、$Z \sim \mathcal{N}(0,1)$のとき$Z^2 \sim \mathrm{Ga}(1/2,2)$が成立すると考えることができる。$\mathrm{Ga}(1/2,\beta)$に従う確率変数を$\beta, Z^2$などを用いて表せ。
v) ガンマ分布の再生性に基づいて乱数$U_1, U_2, \cdots U_n \sim \mathrm{Uniform}(0,1), \, \mathrm{i.i.d.,}$と$Z \sim \mathcal{N}(0,1)$を用いて$\displaystyle \mathrm{Ga} \left( n+\frac{1}{2},\beta \right)$に従う乱数を生成する式を答えよ。
・解答
i)
確率密度関数$f_1(x), f_2(y)$はそれぞれ下記のように表すことができる。
$$
\large
\begin{align}
f_1(x) &= \frac{1}{\displaystyle 2^{\frac{1}{2}} \Gamma \left( \frac{1}{2} \right)} x^{\frac{1}{2}-1} \exp{\left( -\frac{x}{2} \right)} \\
f_2(y) &= \frac{1}{\displaystyle \beta^{\frac{1}{2}} \Gamma \left( \frac{1}{2} \right)} y^{\frac{1}{2}-1} \exp{\left( -\frac{y}{\beta} \right)}
\end{align}
$$
ⅱ)
変数変換によって$x$を$y$の式で置き換えるので、$\displaystyle \frac{x}{2} = \frac{y}{\beta}$が成立する必要がある。よって下記の変数変換の式が得られる。
$$
\large
\begin{align}
\frac{x}{2} &= \frac{y}{\beta} \\
x &= \frac{2y}{\beta}
\end{align}
$$
ⅲ)
$\displaystyle x = \frac{2y}{\beta}$より、$\displaystyle \frac{dx}{dy} = \frac{2}{\beta}$が成立する。よって、$f_2(y)$は$f_1(x)$の変数変換に基づいて下記のように導出できる。
$$
\large
\begin{align}
f_2(y) &= f_1(x) \left| \frac{dx}{dy} \right| \\
&= f_1 \left( \frac{2y}{\beta} \right) \cdot \frac{2}{\beta} \\
&= \frac{1}{\displaystyle 2^{\frac{1}{2}} \Gamma \left( \frac{1}{2} \right)} \left( \frac{2y}{\beta} \right)^{\frac{1}{2}-1} \exp{\left( -\frac{1}{\cancel{2}} \cdot \frac{\cancel{2}y}{\beta} \right)} \cdot \frac{2}{\beta} \\
&= \frac{\beta^{\frac{1}{2}}}{\displaystyle \cancel{2} \Gamma \left( \frac{1}{2} \right)} y^{\frac{1}{2}-1} \exp{\left( -\frac{y}{\beta} \right)} \cdot \frac{\cancel{2}}{\beta} \\
&= \frac{1}{\displaystyle \beta^{\frac{1}{2}} \Gamma \left( \frac{1}{2} \right)} y^{\frac{1}{2}-1} \exp{\left( -\frac{y}{\beta} \right)}
\end{align}
$$
上記はi)で確認した$f_2(x)$に一致する。
iv)
ⅱ)の式に基づいて$\displaystyle y = \frac{\beta}{2} x$より、下記のように考えることができる。
$$
\large
\begin{align}
\frac{\beta}{2} Z^2 \sim \mathrm{Ga}(1/2,\beta)
\end{align}
$$
v)
$\displaystyle \mathrm{Ga} \left( n+\frac{1}{2},\beta \right)$に従う乱数を生成する式は下記のように得られる。
$$
\large
\begin{align}
\sum_{i=1}^{n} X_i + \frac{\beta}{2} Z^2 = -\beta \log{ \left[ \prod_{i=1}^{n} U_i \right] } + \frac{\beta}{2} Z^2
\end{align}
$$
・解説
下記などを元に作成を行いました。
モンテカルロ法による推定と必要なサンプル数
・問題
モンテカルロ法は乱数を用いて数値計算を行う手法である。この問題では以下、モンテカルロ法を用いた円周率$\pi$の推定法に関して確認し、推定結果の標準偏差に対応する必要なサンプル数に関して考察を行う。下記の問いにそれぞれ答えよ。
i) 原点$(0,0)$を中心とする半径$1$の単位円を考えるとき、第$1$象限の面積を円周率$\pi$を用いて表せ。
ⅱ) $X \sim \mathrm{Uniform}(0,1), \, Y \sim \mathrm{Uniform}(0,1)$のように一様分布$\mathrm{Uniform}(0,1)$に基づく乱数$(X,Y)$を発生させる。このとき$X^2+Y^2 \leq 1$である確率がi)の結果に等しいことを確認せよ。
ⅲ) $X_i \sim \mathrm{Uniform}(0,1), \, Y_i \sim \mathrm{Uniform}(0,1)$を元に乱数$(X_i,Y_i), \, i=1,2,\cdots,N$を発生させるとき、$X_i^2+Y_i^2 \leq 1$である乱数が$M$個観測されたと仮定する。このとき、$M, N$を用いて円周率$\pi$の推定量$\hat{\pi}$を表せ。
iv) $\displaystyle M \sim \mathrm{Bin} \left( N,\frac{\pi}{4} \right)$のように確率変数$M$が二項分布に従うことに基づいて$V[M]$を計算せよ。
v) $\hat{\pi}$の分散$\displaystyle V[\hat{\pi}] = V \left[ \frac{4M}{N} \right]$を$\pi,N$を用いて表し、$SD[\hat{\pi}]=\sqrt{V[\hat{\pi}]} \leq 0.01$が成立する際の$N$の最小値を計算せよ。ただし$\pi \simeq 3.14$を用いて良い。
・解答
i)
半径$1$の円の面積が$\pi$であることから、単位円の第$1$象限の面積は$\displaystyle \frac{\pi}{4}$である。
ⅱ)

上図の緑の正方形の$1$辺の長さは$1$であるので、正方形の面積は$1$である。i)より円の面積は$\displaystyle \frac{\pi}{4}$であることから$X^2+Y^2 \leq 1$である確率は$\displaystyle \frac{\pi}{4}$に一致する。
ⅲ)
$\displaystyle \frac{M}{N} = \frac{\hat{\pi}}{4}$であるので、推定量$\hat{\pi}$は下記のように表せる。
$$
\large
\begin{align}
\frac{M}{N} &= \frac{\hat{\pi}}{4} \\
\hat{\pi} &= \frac{4M}{N}
\end{align}
$$
iv)
確率変数$X$が$X \sim \mathrm{Bin}(n,p)$のように二項分布$\mathrm{Bin}(n,p)$に従うとき、$V[X]=np(1-p)$である。よって$V[M]$は下記のように表せる。
$$
\large
\begin{align}
V[M] = N \cdot \frac{\pi}{4} \cdot \left( 1 – \frac{\pi}{4} \right)
\end{align}
$$
v)
$\displaystyle V[\hat{\pi}] = V \left[ \frac{4M}{N} \right]$より、$V[\hat{pi}]$は下記のように計算できる。
$$
\large
\begin{align}
V[\hat{\pi}] &= V \left[ \frac{4M}{N} \right] = \frac{4^2}{N^2} V[M] \\
&= \frac{4^2}{N^2} \times N \cdot \frac{\pi}{4} \cdot \left( 1 – \frac{\pi}{4} \right) \\
&= \frac{\pi(4-\pi)}{N}
\end{align}
$$
よって、$SD[\hat{\pi}]=\sqrt{V[\hat{\pi}]} \leq 0.01$は下記のように表せる。
$$
\large
\begin{align}
SD[\hat{\pi}] & \leq 0.01 \\
\sqrt{V[\hat{\pi}]} & \leq 0.01 \\
\frac{\pi(4-\pi)}{N} & \leq 0.01^2 \\
N & \geq 10000 \times 3.14 \times (4-3.14) \\
N & \geq 27004
\end{align}
$$
上記より$N$の最小値は$27004$であると考えられる。
・解説
$\pi$が推定対象であることからv)では$\pi \simeq 3.14$のように小数点$2$桁までを計算に用いました。
下記などに基づいて問題の作成を行いました。
参考書籍
・自然科学の統計学(東京大学出版)
