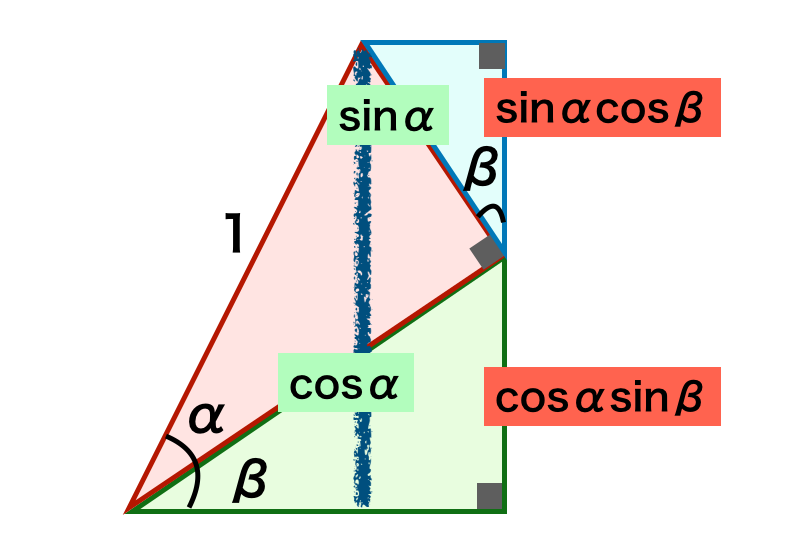
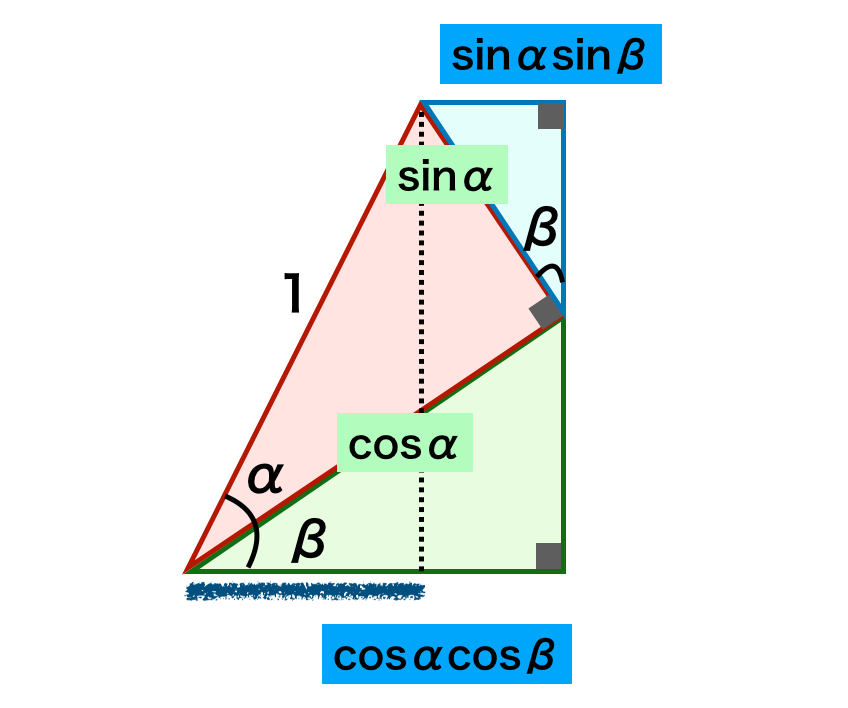
最尤法は観測値のみを元に推定を行うが、トピックによっては事前知識がわかっている場合や、サンプル数が少ない場合に最尤法が極端な結果を示す場合の補正にあたって、事前分布に基づくベイズ法は役に立つ。事前分布やMAP推定、予測分布が理解できるように演習を取り扱った。https://www.hello-statisticians.com/explain-books-cat/math_stat_practice_ch14.html
・標準演習$100$選https://www.hello-statisticians.com/practice_100
基本問題 ベイズの定理と事前分布・事後分布 ・問題
i) 事象$A,B$がある際に、$A \cap B$は条件付き確率を元に下記のように表せる。
上記の式が妥当であることを直感的に解釈せよ。
ⅱ) $(1)$式より、$P(A|B)$を$P(B), P(B|A), P(A)$を用いて表せ。
ⅲ) ⅱ)の式がベイズの定理の式に一致する。以下ではベイズの定理を最尤法に適用する流れに関して二項分布を例に確認を行う。$X \sim \mathrm{Bin}(n,p)$の確率関数$p(x)=P(x|p)$は下記のように表せる。
ここで$n$回のベルヌーイ試行に基づいて観測値$X=x$が得られた際に$p$の推定を行うことを考える。最尤推定は尤度を$L(p)=P(x|p)$とおき、$L(p)$が最大になる$p$を導出する手法である。
iv) $n=2$のとき、ⅲ)の式を用いて$x=0,1,2$に関して$p$の推定を行え。
v) $n=2$のようにサンプルが少ない場合、iv)の推定結果は$x$の値次第で大きく変動する。この変動の緩和にあたって下記のように事前分布$P(p)$を導入することを考える。
ここで$P(x)=c(x)$のように表すとき、ベイズの定理に基づいて事後分布$P(p|x)$を表せ。
vi) v)で得られた事後分布$P(p|x)$が最大になる$p$を$n, x$を用いて表せ。
・解答
ⅱ)
ⅲ)
iv)
v)
vi)
上記を$p$に関して微分すると下記が得られる。
上記は$p$に関して単調増加であるので、$\log{L(p)}$や$L(p)$は$\displaystyle p = \frac{x+1}{n+2}$のとき最大値を取る。
vⅱ)
・解説二項分布の共役事前分布と事後分布の解釈 」で取り扱いました。
二項分布の共役事前分布と事後分布の解釈 ・問題
ベイズ法ではパラメータの推定にあたって、下記のように事後分布の$P(\theta|x)$が事前分布の$P(\theta)$と尤度の$p(x|\theta)$の積に比例することを利用する。
上記の式は多くの書籍などで出てくるが、抽象的な表記より具体的な確率分布を例に考える方がわかりやすい。以下では二項分布に関して$(1)$式を表すことを考える。
ここまでの内容を元に下記の問いに答えよ。
・解答
ⅱ)
ⅲ)
iv)
v)
vi)
vⅱ)
・解説
ポアソン分布の共役事前分布と事後分布の解釈 ・問題
ポアソン分布の確率関数を$f(x|\lambda)$とおくと、$f(x|\lambda)$は下記のように表される。
ここで観測値$x_1, x_2, …, x_n$が観測される同時確率を$P(x_1,…,x_n|\lambda)$とおくと、$P(x_1,…,x_n|\lambda)$は下記のように表すことができる。
上記を$\lambda$の関数と見ると、ガンマ分布の形状と一致するので、$\lambda$の事前分布$P(\lambda)$に$Ga(a,1)$を考える。このとき$P(\lambda)$は下記のように表すことができる。
ここまでの内容を元に以下の問題に答えよ。
・解答
ⅱ)
ⅲ)
iv)
v)
上記より、$n$が大きくなるにつれて$E[\lambda], E[\lambda|x_1,x_2,…,x_n]$が標本平均の$\bar{x}$に近づき、$V[\lambda], E[\lambda|x_1,x_2,…,x_n]$が$0$に近づくことがわかる。
これは$n$が大きくなるにつれて最尤推定の結果に近づくことを意味し、ベイズの定理を用いた推定が最尤法の拡張であると考えることができることを表している。
・解説https://www.hello-statisticians.com/explain-terms-cat/conjugate_dist1.html
ⅲ)で取り扱ったガンマ分布のモーメント母関数に関しては下記で詳しい導出を行いましたので、こちらも参考になると思います。https://www.hello-statisticians.com/explain-books-cat/toukeigaku-aohon/ch1_blue_practice.html#19
v)の結果の解釈は最尤法とベイズを比較する際によく出てくるので、事後分布を用いた推定結果の解釈に関してはなるべく行うようにすると良いと思います。
正規分布の共役事前分布の設定と事後分布 ・問題
この計算は重要なトピックである一方で平方完成に関連する計算が複雑になり、計算ミスなどが起こりやすい。この問題では以下、関連の計算について可能な限りシンプルに計算ができるように導出の流れの確認を行う。
以下の問題に答えよ。
・解答
ⅱ)
ⅲ)
よって同時確率密度関数$f(x_1,…,x_n|\mu,\sigma^2)$は下記のように変形できる。
上記のように同時確率密度関数を$\mu, \bar{x}$の関数と$x_i,\bar{x}$の関数に分解することができたのでFisher-Neymanの定理より$\bar{x}$が$\mu$の十分統計量であることが示せる。
iv)
v)
$g(x)$は$a>0$から下に凸の関数であるので、上記より、$\displaystyle x = -\frac{b}{2a}$のとき$g(x)$は最小値を取ることがわかる。
vi)
vⅱ)
ここで事後分布の平均は$\bar{x}$と$\lambda$を$n \tau^2:\sigma^2$に内分する点であることが確認でき、$n$が大きい時は$\bar{x}$に限りなく近づくことも同時にわかる。
・解説https://www.hello-statisticians.com/explain-terms-cat/conjugate_dist1.html#i-6
ⅲ)のようにFisher-Neymanの定理の式の形で同時確率密度関数、尤度を表すことで$\mu$に関連する部分の表記をシンプルに行えます。このような表記を用いることで、vi)での計算で$\displaystyle \sum$を考えなくてよく、これにより式が見やすくなります。
vi)の計算にあたってはv)のように全ての項を考えるのではなく、v)の結果を活用しさらに$\propto$を用いて定数項は考えないことで計算をシンプルに行うことができます。
EAP推定量とMAP推定量 ・問題
この問題では以下、EAP推定量とMAP推定量に関して具体的な事後分布に基づいて確認するにあたって、「ベータ分布」、「ガンマ分布」、「正規分布」に対してそれぞれEAP推定量とMAP推定量の導出を行う。「ベータ分布$\mathrm{Be}(\alpha,\beta)$」、「ガンマ分布$\mathrm{Ga}(\alpha,\beta)$」、「正規分布$\mathcal{N}(\mu,\sigma^2)$」の確率密度関数を$f_1(x),f_2(x),f_3(x)$とおくとそれぞれ下記のように表すことができる。
ここまでの内容に基づいて下記の問いにそれぞれ答えよ。二項分布の共役事前分布と事後分布の解釈 」では、二項分布$\mathrm{Bin}(n,p)$の確率パラメータ$p$の事後分布にベータ分布$\mathrm{Be}(\alpha+x,\beta+n-x)$が得られた。このとき$p$のEAP推定量$\hat{p}_{EAP}$とMAP推定量$\hat{p}_{EAP}$を$n,x,\alpha,\beta$を用いて表せ。
・解答
ⅱ)
ⅲ)
iv)
v)
$\hat{\lambda}_{MAP}$の計算にあたっては$\log{f_2(\lambda)}$を考え、$\lambda$で微分を行えばよい。$\log{f_2(\lambda)}$は下記のように表すことができる。
上記を$\lambda$で偏微分を行うことで下記が得られる。
vi)
・解説ポアソン分布の共役事前分布と事後分布の解釈 」と「正規分布の共役事前分布の設定と事後分布 」で取り扱いました。ⅱ)〜iv)では事後分布のパラメータを元に推定量の計算を行いましたが、このように計算すると式が複雑になるので、v)、vi)のように「①それぞれの確率分布に関する推定量の計算」と「②事後分布のパラメータの計算」を分けて考えるとシンプルに取り扱えて良いのではないかと思います。v)、vi)では簡略化にあたって②は省略し、①のみ取り扱いました。
発展問題 共役事前分布と指数型分布族 予測分布 ・問題
予測を行うにあたっては、「EAP推定量とMAP推定量 」で考えたように事後分布を元にパラメータの推定量を計算し、推定量を元に予測を行うのがシンプルである。が、新規のサンプル$x_{n+1}$に関して下記を考えることで予測を行うことも可能である。
上記に基づいて定められる$P(x_{n+1}|x_1,\cdots,x_n)$を予測分布(Predictive distribution)という。以下、標本がポアソン分布に基づいて観測された際の予測分布の導出に関して演習形式で確認を行う。下記の問いにそれぞれ答えよ。
・解答
ⅱ)
ⅲ)
iv)
上記より、$\lambda$の事後分布はガンマ分布$\displaystyle \mathrm{Ga} \left( 18,\frac{1}{7} \right)$であると考えることができる。
v)
vi)
vⅱ)
・解説
参考