
SimCLRのような対照学習(Contrastive Learning)の枠組みを用いることで画像のベクトル表現の抽出が可能です。当記事では画像とテキストのベクトル表現の抽出をmulti-modalに行った研究であるCLIPについて取りまとめを作成しました。
CLIPの論文である「Learning Transferable Visual Models From Natural Language Supervision」の内容を参考に作成を行いました。
・用語/公式解説
https://www.hello-statisticians.com/explain-terms
前提の確認
SimCLR
SimCLRについては下記で詳しく取りまとめました。
CLIP
CLIPの処理の概要と対照学習
CLIP(Contrastive Language-Image Pre-training)論文の処理の全体像は下図を確認すると理解しやすいです。
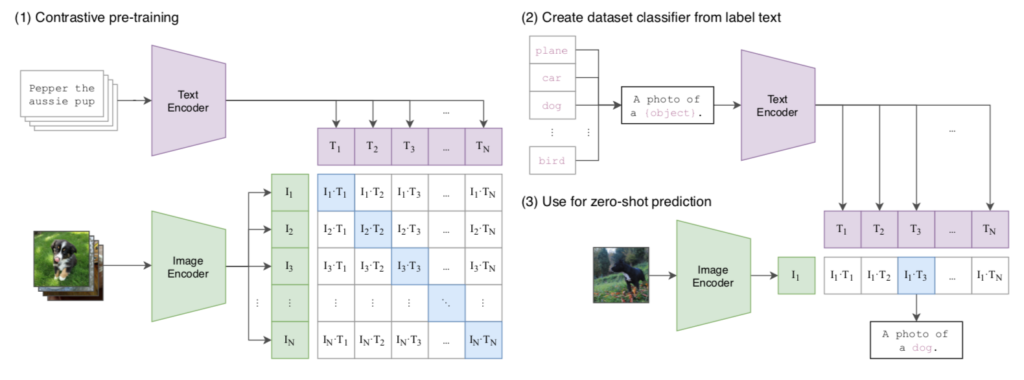
上図の$(1)$は対照学習(Contrastive Learning)に基づく学習プロセス、$(2)$と$(3)$は推論プロセスにそれぞれ対応します。
対照学習を用いた学習プロセスでは$N$個の画像とテキストの組を用意し、$N \times N$の対応について類似度計算を行うようにします。このとき、それぞれの行について対角成分のみを正解と見なし学習を行います。基本的な学習の流れはCLIP論文のFigure$\, 3$の擬似コードを確認すると良いです。

上記の計算はSimCLRの学習におけるlossの計算と基本的には同様な計算です。このような学習を行うことで、画像とテキストに関するマルチモーダルなベクトル表現の獲得が可能になります。
このような学習によって得られるベクトル表現の活用である$(2)$と$(3)$については次項で確認します。
CLIPの学習結果を用いたzero-shot分類
CLIPは画像とテキストが同じペアであるかの判定を行うことによって、zero-shot分類を行うことが可能です。
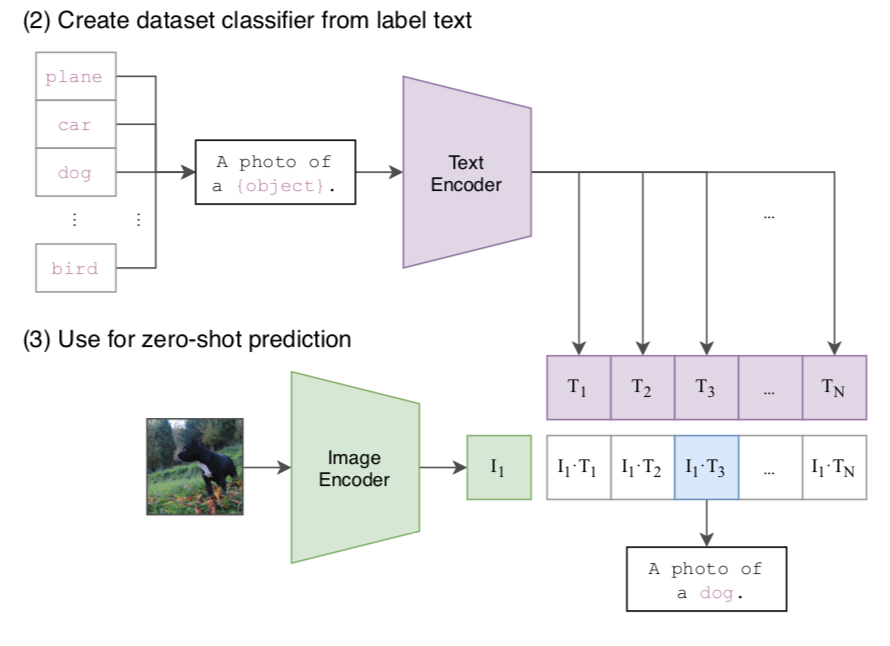
たとえば上図のようにCLIPで学習を行ったText EncoderとImage Encoderを用いてEmbedding(ベクトル表現)をそれぞれ計算し、コサイン類似度を計算することで分類を行うことができます。$(2)$のText Encoderの使い方については「A photo of a plane.」の入力に対応するText Encoderの出力が$T_1$、「A photo of a car.」の入力に対応する出力が$T_2$などのようにテキストのベクトル表現$T_i$を生成し、$I_1$との類似度を計算すると理解すると良いです。
図の計算結果では「A photo of a car.」に対応する出力である$T_3$とImage Encoderの出力の$I_1$の類似度が高いことから、zero-shot分類の結果は「A photo of a dog.」が出力されます。