当記事は「現代数理統計学(学術図書出版社) 」の読解サポートにあたってChapter.3の「多次元の確率変数 」の章末問題の解説について行います。
基本的には書籍の購入者向けの解説なので、まだ入手されていない方は購入の上ご確認ください。また、解説はあくまでサイト運営者が独自に作成したものであり、書籍の公式ページではないことにご注意ください。(そのため著者の意図とは異なる解説となる可能性はあります)
↓下記が公式の解答なので、正確にはこちらを参照ください。https://www.gakujutsu.co.jp/text/isbn978-4-7806-0860-1/
章末の演習問題について
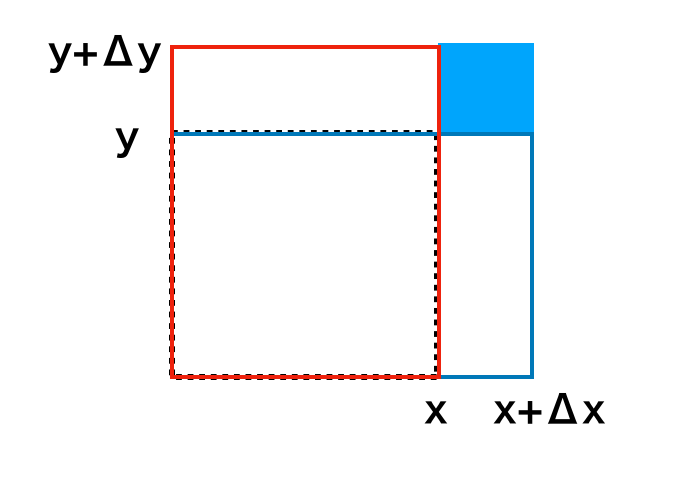
問題3.1の解答例
上図のように考えることで示すことができる。
問題3.2の解答例
$$
・連続分布の場合
・離散分布の場合
問題3.3の解答例
$(3.29)$式より、$r$と$\theta$が独立かつ、$\theta$は$0 \leq \theta \leq 2\pi$の一様分布に従うことがわかる。
また、$v=r^2$を用いて変数変換を行うことを考える。変換後を$g(v,\theta)$のようにおくと、下記のように計算を行うことができる。
問題3.4の解答例
問題3.5の解答例
$Z = a_1X_1 + a_2X_2 + … + a_nX_n$を考えた際、$Z$の分散$V[Z]$は分散の定義より下記のように表すことができる。
上記より、式$(3.37)$が成立することを示すことができる。
問題3.6の解答例
$$
上記のように$n$次元確率ベクトルの$\mathbf{X}$を定義する。$(3.40)$式は$n$次元の定数ベクトル$\mathbf{a}$と$n$次の定数行列$\mathbf{B}$に関して下記のように表される。
以下、上記の$(1)$式を示す。
上記の期待値を取ることで、$E[\mathbf{a} + \mathbf{B}\mathbf{X}]$は下記のように表せる。
上記より$(1)$式は示すことができる。
問題3.7の解答例
・$(3.42)$式の導出
上記の両辺の期待値を取り、$E[(\mathbf{X}-\mathbf{\mu})(\mathbf{X}-\mathbf{\mu})^{T}]$を考えると下記のように変形できる。
・$(3.43)$式の導出
問題3.8の解答例
ポアソン分布、正規分布に関する再生性は下記で導出を行なったため省略する。
・ポアソン分布 https://www.hello-statisticians.com/explain-terms-cat/probdist3.html#i-5
・正規分布 https://www.hello-statisticians.com/explain-terms-cat/probdist3.html#i-8
以下、負の二項分布とガンマ分布に関して確認する。
・負の二項分布
ここ負の二項分布のモーメント母関数を$m(t)$とおくと、$m(t)=G(e^t)$より、$m(t)$は下記のように表せる。
ここで確率変数$X_1$はパラメータ$p, q=1-p, r_1$の負の二項分布$NB(r_1,p)$に従い、確率変数$X_2$はパラメータ$p, q=1-p, r_2$の負の二項分布$NB(r_2,p)$に従うとする。また、このときのモーメント母関数を$m_{X_1}(t), m_{X_2}(t)$でおくことを考える。これに対して確率変数$X=X_1+X_2$に関するモーメント母関数を$m_{X}(t)$とすると、$m_{X}(t)$は下記のように表すことができる。
・ガンマ分布
ここで確率変数$X_1$はパラメータ$\nu_1, \alpha$のガンマ分布$Ga(\nu_1, \alpha)$に従い、確率変数$X_2$はパラメータ$\nu_2, \alpha$のガンマ分布$Ga(\nu_2, \alpha)$に従うとする。また、このときのモーメント母関数を$m_{X_1}(t), m_{X_2}(t)$でおくことを考える。これに対して確率変数$X=X_1+X_2$に関するモーメント母関数を$m_{X}(t)$とすると、$m_{X}(t)$は下記のように表すことができる。
上記より、$(3.51)$式の$Ga(\nu_1, \alpha)*Ga(\nu_2, \alpha) = Ga(\nu_1+\nu_2, \alpha)$が導出できる。
問題3.9の解答例
連続分布の場合に関して以下示す。$x, y$の同時確率密度関数を$f(x,y)$、確率変数$X$に関する周辺密度関数を$f_{X}(x)$と定義する。このとき、$E[g(X,Y)]$は下記のように変形できる。
上記より$(3.55)$式を示すことができる。
問題3.10の解答例
$E[(Z-c)^2]$は下記のように変形できる。
$(c-E[Z])^2$は$c$に関して下に凸の二次関数であるので、上記より$E[(Z-c)^2]$を最小にする$c$は$c = E[Z]$であることがわかる。
問題3.11の解答例
$$
上記のように$(3.62)$式、$(3.63)$式が与えられる。ここで$(3.63)$式を$(3.62)$式に代入する。
上記が$(3.64)$式に一致するので、$(3.64)$式を示すことができる。
次に、下記のように(1)式を$b_i$について偏微分し$0$とおく。
ここで、上記の左辺の第$2$項と第$3$項についてそれぞれ微分を考える。
・第$3$項
第$2$項、第$3$項の計算結果を$(2)$式に代入し、下記のように整理を行う。
$(3)$式が$(3.65)$式に一致するので、$(3.65)$式を示すことができる。
問題3.12の解答例
$n!$通りの並べ方を考えた上で、左から$y_1, y_2, …, y_n$のようにグループを割り当てていくと考えればよい。
このとき、同一のグループに所属するものの順番は考慮しないので、それぞれ$y_i!$通りの重複が生じる。よって、多項係数は下記のように表すことができる。
また、多項分布の確率$P(Y_1=y_1, …, Y_n=y_n)$は下記のように表すことができる。
問題3.13の解答例
問題3.14の解答例
$$
$$
このとき、上記のように$\mathbf{X}, \mathbf{t}$を定義し、モーメント母関数$m(\mathbf{t}) = E[e^{\mathbf{t}^{T} \mathbf{X}}]$を考える。
上記の指数関数部分に対し、$\mathbf{x}$に関する平方完成を行うことを考える。
上記の右辺の$1$項目は積分により消えるため、モーメント母関数の下記が導出できる。
問題3.15の解答例
$\mathbf{x}, \mathbf{y}, \mathbf{a}$はそれぞれ下記のような$n$次元ベクトルで定義できる。
$\mathbf{B}$が$n$次の正則行列であるので、$\mathbf{y} = \mathbf{a} + \mathbf{B}\mathbf{x}$は下記のように変形できる。
ここで$\mathbf{B}’ = \mathbf{B}^{-1}$を下記のように定義する。
ここで、$J(\partial x / \partial y)$は下記のように計算できる。
ここまでの議論により$J(\partial x / \partial y) = \mathbf{B}^{-1}$を示すことができる。
問題3.16の解答例
$$
ここで$(1)$式の両辺を$\displaystyle \frac{f_{Y,Z}(y,z)}{f_{Z}(z)}$で割ると下記のようになる。
問題3.17の解答例
「$(3.18)$が成立 $\implies$ $f(x,y,z)=g(x,z)h(y,z)$」と「$f(x,y,z)=g(x,z)h(y,z)$ $\implies$ $(3.18)$が成立」に分けて示す。
・「$(3.18)$が成立 $\implies$ $f(x,y,z)=g(x,z)h(y,z)$」に関して
上記の$(3.18)$式は条件付き確率の定義に基づいて、下記のように表すことができる。
ここで$(1)$式の両辺に$f_{Z}(z)$をかけると下記のようになる。
・「$f(x,y,z)=g(x,z)h(y,z)$ $\implies$ $(3.18)$が成立」に関して
このとき$f(x,y,z)=g(x,z)h(y,z)$より、下記のように表記することもできる。
このとき条件付き確率分布の$f_{X,Y|Z}(x,y)$は下記のように表すことができる。
問題3.18の解答例
$$
上記のように考え、$X_i, Y_i \in \left\{0, 1 \right\}$であることを考慮すると、$(Z_i, X_i-Z_i, Y_i-Z_i, 1-X_i-Y_i+Z_i)$はどれか$1$つのみが$1$でその他が$0$に対応する。これは$4$次元のベルヌーイ試行になる。また、$(Z_i, X_i-Z_i, Y_i-Z_i, 1-X_i-Y_i+Z_i)$のそれぞれの和が$(Z, X-Z, Y-Z, n-X-Y+Z)$に対応するので、これは$4$項分布に従うことを意味する。このとき、確率変数$(Z_i, X_i-Z_i, Y_i-Z_i, 1-X_i-Y_i+Z_i)$の成功確率は$p_1p_2, p_1(1-p_2), (1-p_1)p_2, (1-p_1)(1-p_2)$にそれぞれ対応する。
この$4$項分布の確率関数$P(z,x-z,y-z,n-x-y+z|p_1p_2, p_1(1-p_2), (1-p_1)p_2, (1-p_1)(1-p_2))$は下記のように表すことができる。
また、$X, Y$はそれぞれ独立に二項分布に従い、それぞれの確率関数$P(x,n-x|p_1,n), P(y,n-y|p_2,n)$は下記のように表すことができる。
よって、$X, Y$が与えられた際の$Z$の条件付き分布$P(X=x,Y=y|Z=z)$は下記のようになる。
・考察
問題3.19の解答例
$$
上記に関して逆変換の導出を行う。$(2)$式を変形した$x=vy$を$(1)$式に代入する。
上記で得られた$y$を$x=vy$に代入すると下記が得られる。
よって、下記のような逆変換が得られる。
$(3)$式、$(4)$式で表した逆変換に基づいて、ヤコビ行列$\mathbf{J}$を下記のように考える。
$(5)$式を元にヤコビアン$|\det \mathbf{J}|$の計算を行う。
次に確率密度関数について考える。$X,Y$に関する確率密度関数の$f(x,y)$は、下記のように表すことができる。
$0 \leq x \leq 1, 0 \leq y \leq 1$と$(3)$式、$(4)$式より、$u,v$に関して下記の式が成立する。
$(7)$式、$(8)$式を元に、$0 \leq x \leq 1, 0 \leq y \leq 1$に対応する$u,v$に対して$\displaystyle g(u,v) = f(x,y)|\det \mathbf{J}|$を考える。
また、$V$に関する周辺密度関数$g(v)$は$(9)$式を$u$に関して積分することで得られる。
・考察
まず$g(u,v)$に関しては、上記のように図示を行った。赤線があるところが確率密度関数の$g(u,v)$が$0$ではない領域を表しており、$v$が$0$に近い方が確率密度関数の値が大きくなることは線の幅で表した。
次に周辺密度関数の$g(v)$に関しては上記のように表した。$v \leq 1$では一様分布であり、$v>1$では$1/v^2$に一致することを抑えておくと良いと思われる。
問題3.20の解答例
確率変数$Z$が連続である場合と離散である場合に分けて示す。
・$Z$が連続
上記を$c$で微分すると下記のようになる。
$c$に関する最小値を考えるので、$\displaystyle \frac{d E[|Z-c|]}{dc} = 0$より、下記が成立する。
確率の定義より$P(Z \leq c) + P(Z > c) = 1$となるので、下記が成立する。
・$Z$が離散 $E[|Z-c|]$は確率関数の$p(z)$を用いて下記のように表すことができる。
上記を$c$で微分すると下記のようになる。
上記は連続の場合と同じ式であり、連続の場合と同様に$P(Z \leq c) + P(Z > c) = 1$を用いて、$E[|Z-c|]$を最小にする定数$c$は$Z$の分布のメディアンであることを示すことができる。
問題3.21の解答例