
データの可視化(data visualization)は、データを様々な角度から確認し、データ自体を理解する目的で行われることが多い印象です。探索的データ分析(EDA)と呼ばれることもあります。Pythonを使ってデータを可視化する際に、matplotlibがよく使われていると思います。ですが、matplotlibだけで綺麗で複雑な図を作成するのは難しいことが多いです。 ここでは、matplotlibベースのデータ可視化ライブラリであるseabornの基礎をまとめます。
seabornを利用することで、簡単に綺麗な図を作ることができます。
Contents
seaborn
seabornは、Pythonのデータ可視化(data visualization)ライブラリです。matplotlibをベースにしており、レイアウトの指定をしておくと、matplotlibで描くグラフがそれだけで綺麗になります。また、複数のプロットを組み合わせたグラフなどを描画する高度なAPIも提供されています。
詳細は以下の公式ドキュメントを参照してください。公式ドキュメントにあるGallaryを眺めるだけでも楽しいですし、どんなことができるのかわかると思います。
seabornの導入
インストール
インストールはpip を利用できます。詳細は下記の公式インストールドキュメントを参照してください。
https://seaborn.pydata.org/installing.html
pipでインストールをするには下記のコマンドを実行します。
pip install seabornseabornはじめの一歩
seabornの基本的な利用方法として下記の例を紹介します。
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme()
xs = np.random.normal(size=500)
plt.hist(xs);matplotlibでヒストグラムを描画しています(matplotlibでのヒストグラムの描画についてはこちらを参照ください)。こちらのコードを実行すると以下のような図が描画されます。
こちらにあるようなmatplotlibを使った通常のグラフと配色などが異なりますね。こちらについて解説します。
import seaborn as snsこの行でseabornをimportしています。
sns.set_theme()このコマンドによって、本プロセスにおけるmatplotlibとseabornで描画する全てのグラフのテーマを設定します。そのため、matplotlibで描画したヒストグラムの配色等が変わってきています。なお、ここでは引数に何も入れていないので、デフォルトテーマが使われます。
詳しくは、以下の公式ドキュメントを参照してください。
https://seaborn.pydata.org/generated/seaborn.set_theme.html
テーマについては、本稿の「レイアウトの指定」にも簡単な解説を記載しています。
基本的なグラフ描画
上記の通り、seabornをインポートしてテーマを設定するだけで、matplotlibで描画するグラフの見た目が改善されます。これだけでもseabornを利用する効果はあるのですが、ここでは、seabornで描画できるグラフの例をいくつか紹介します。
散布図
散布図(lmplot)
ヒストグラム(KDE)
棒グラフ
seabornで特徴的なグラフ描画
散布図行列: pairplot
多変量データのうち二変数同士の組み合わせで散布図を描画することで、どの変数間に相関があるのかを確認する目的で「散布図行列」というものを描くことが多いです。散布図行列をmatplotlibで愚直に描画するには、sub_plotを駆使する必要があり、複雑になります。seabornには、seaborn.pairplotが提供されており、散布図行列を容易に描画することができます。
詳細は以下のドキュメントを確認してください。
データとしてpandas.DataFrame形式のデータが用意できれば、そのデータを入力するだけです。例として、irisデータセットの散布図行列を描画します。
import seaborn as sns
df_iris = sns.load_dataset("iris")
sns.pairplot(df_iris);上記のコードを実行すると下記のようなグラフが描画されます。
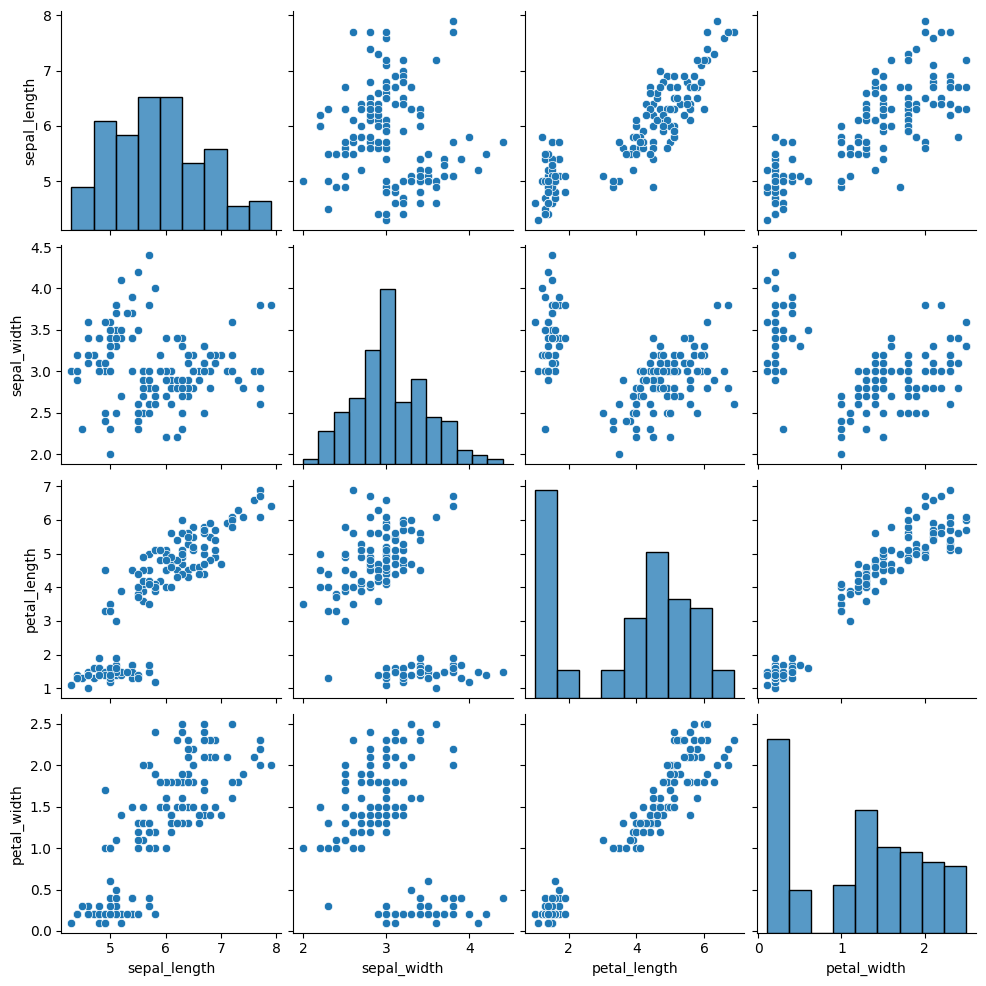
irisデータセットは、4つの数値データとあやめ(iris)の種類を表す列(species)で構成されます。なお、データセットの取得(seaborn.load_dataset)については、後述の「豊富なデータセット」を確認してください。
species列はobject型(カテゴリデータ)なので、その他の4つの変量の2つの組み合わせの散布図が描画されています。対角成分には、各変量のヒストグラムが描かれています。
seaborn.pairplotのオプションパラメータとして、hueでカテゴリ変数を指定すると、指定したカテゴリで色分けがされます。
df_iris = sns.load_dataset("iris")
sns.pairplot(df_iris, hue="species");上記のコードを実行すると以下のような図が描画されます。
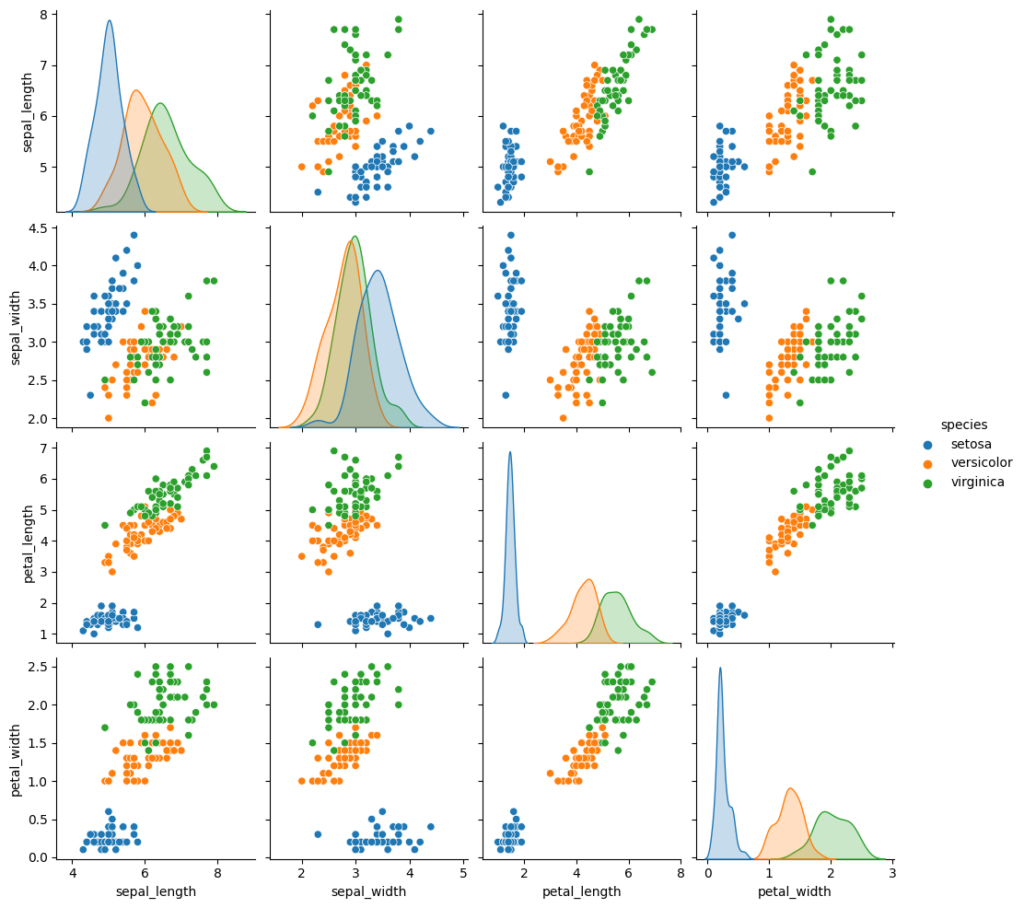
アヤメの種類の分類に寄与する変量としてどのようなものが適切か容易に確認できます。
[参考]
jointplot
heatmap
覚えておくと良いポイント
レイアウトの指定
seabornでは、グラフの配色やフォントサイズなどを一括で変更できる seaborn.set_theme が提供されています。詳細は公式ドキュメントを参照ください。ここでは、よく使うcontext、style、palette について解説します。
context
contextは、描画要素のスケールを指定します。
設定はプリセットを呼び出す形式で、「paper, notebook, talk, poster」のいずれかを入力します。デフォルトはnotebookが選択されます。
paper, notebook, talk, posterの順にスケールが拡大されていきます。
sns.set_theme()
xs = np.random.normal(size=500)
plt.hist(xs);このコードを実行すると下記のグラフが描画されます。
次に、talkを指定してみます。
sns.set_theme(context="talk")
plt.hist(xs);下記のようなグラフが描画されます。
フォントサイズが変わっているのがわかります。
style
styleは描画の背景の色やグリッド線の有無などを指定するプリセットが用意されています。
指定できるパラメータは、darkgrid, whitegrid, dark, white, ticks で、デフォルトでは、darkgridが指定されます。
例として、whitegridを指定する場合は下記のようになります。
sns.set_theme(style="whitegrid")
plt.hist(xs);上記コードを実行すると下記のようなグラフが描画されます。
背景色が白になります。
palette
paletteでは、カラーパレットを指定できます。
指定できる値は、seabornのパレット名(deep, muted, bright, pastel, dark, colorblind)、matplotlibのカラーマップ名(こちらを参照)などが指定できます。詳しくは公式ドキュメントを参照してください。
例として、以下のコードを紹介します。
sns.set_theme(palette="pastel")
plt.hist(xs);上記コードを実行すると以下のような図が描画されます。
[参考]
カラーパレットの指定
カラーパレットは上記のように、全体のテーマを一括で設定できます。カラーパレットで指定される色はseaborn.color_paletteで取得できます。
複数のグラフをプロットする場合など、描画要素を追加する毎に自動で色が遷移します。しかし、色の指定を明示的にしたい場合には、以下のようにカラーコードを格納しておくと便利です。
c_list = sns.color_palette("deep").as_hex()
print(c_list)上記のコードを実行すると、下記のような出力が得られます。

この例では、c_list変数にdeepで指定される10種類の色が16進数で格納されます。グラフを描画する際にこの値を指定できます(下記)。
x = [0, 1, 2, 3, 4, 5]
y1 = [0, 2, 1, 3, 2, 4]
y2 = [4, 2, 3, 1, 3, 2]
plt.plot(x, y1, color=c_list[2])
plt.plot(x, y2, color=c_list[1])上記のコードを実行すると以下のような図が描画されます。
下記のようにリストのindexが色の種類の範囲を超えないように指定できます。(seabornに限った話ではありませんが)
n_color = len(c_list)
ys = np.random.normal(size=15)
for i, y in enumerate(ys):
plt.bar(i, y, color=c_list[i%n_color])上記のコードを実行すると下記のような図が描画されます。
色のローテーションができていることがわかります。
カラーパレットについてさらに詳しくは、以下のチュートリアルなどを参照してください。
[参考]
豊富なデータセット
seabornでは色々なデータセットが用意されており、それらのデータセットを取得できるAPIが提供されています。
例えば、有名なトイデータであるアヤメの種類に関するデータセット(iris)を取得するには下記のようにします。
iris = sns.load_dataset("iris")これで、pandas.DataFrame形式でデータセットを取得することができます(下記)。
取得できるデータセットは、以下のリポジトリのCSVファイル名を指定できます。
https://github.com/mwaskom/seaborn-data
また、データセット名を取得するためのseaborn.get_dataset_namesも用意されています。
[参考]