
Transformerに基づくLLMの学習にあたっては多くの文書を用いる一方で、単語をそのまま取り扱うとEmbedding処理のパラメータ数が増大します。当記事ではこの解決にあたって用いられる手法の$1$つであるBPE(Byte Pair Encoding)のアルゴリズムの仕組みとPythonプログラムの確認を行いました。
・用語/公式解説
https://www.hello-statisticians.com/explain-terms
BPEアルゴリズム
BPEの基本的な仕組み
BPE(Byte Pair Encoding)の基本的な仕組みは下図を元に理解することができる。
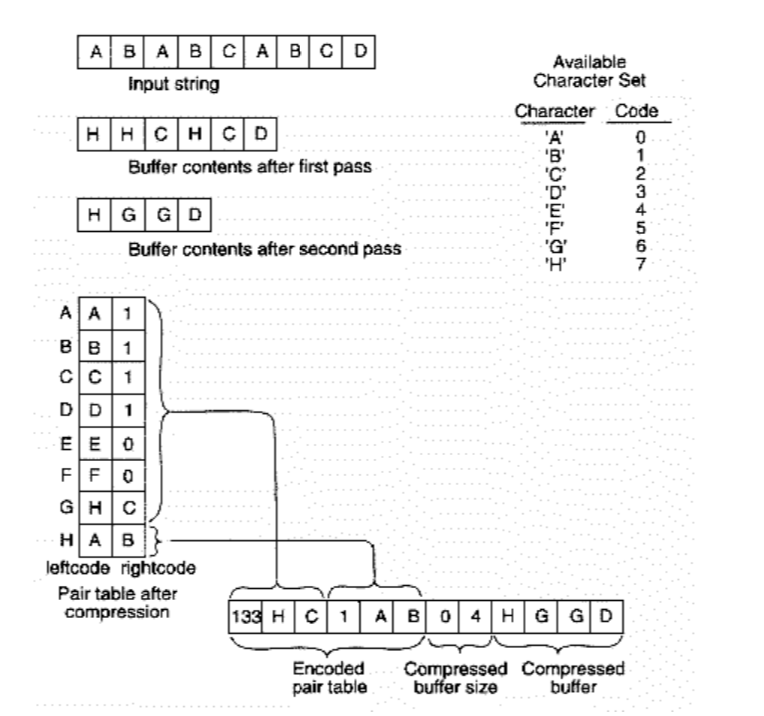
上図では入力が”ABABCABCD”であり、”A”、”B”、”C”、”D”の$4$種類の文字で文字列が構成される。ここで”AB”の並びが最多の$3$回確認できるので”AB”を”H”で置き換えると、文字列は”HHCHCD”に変換できる。
次に”HHCHCD”の文字列では”HC”の並びが最多の$2$回観測されるので”G”で置き換えると文字列は”HGGD”に変換できる。BPEではこのように取得した”G”と”H”を加えた”A”、”B”、”C”、”D”、”G”、”H”で文字列を表す。
BPEの論文
BPE(Byte Pair Encoding)を用いる際に参照されることが多いのが「Neural Machine Translation of Rare Words with Subword Units(Sennrich et al., $2016$)」である。
上記はByte Pair Encodingを用いた機械翻訳の論文である一方で、Byte Pair Encodingについては”A New Algorithm for Data Compression(Gage, $1994$)”を参照している。
近年の論文ではBPEを示すにあたって新しいものが参照されることが多いので注意が必要である。当記事でも以下、近年の論文に倣い「Neural Machine Translation of Rare Words with Subword Units(Sennrich et al., $2016$)」を「BPE論文」と表す。
BPEのPythonプログラム
BPE論文のPythonプログラム
BPE論文のAlgorithm$1$では下記のようにPythonを用いたBPE処理が確認できる。

import re, collections
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
vocab = {'l o w _' : 5, 'l o w e r _' : 2, 'n e w e s t _':6,'w i d e s t _':3}
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(best)・実行結果
('e', 's')
('es', 't')
('est', '_')
('l', 'o')
('lo', 'w')
('n', 'e')
('ne', 'w')
('new', 'est_')
('low', '_')
('w', 'i')上記の出力結果はfor文による繰り返し処理それぞれで連結する文字列の組である。たとえば”e”と”s”は”newest”と”widest”に一度ずつ出現するので、全部で$9$回観測され、全体の中で最多である。
処理の概要については次項で詳しく確認を行う。
処理の概要
以下のプログラムではモジュールの読み込みやget_stats関数とmerge_vocab関数の定義は基本的には省略する。
まず、get_stats(vocab)の実行結果の確認を行う。
vocab = {'l o w _' : 5, 'l o w e r _' : 2, 'n e w e s t _':6,'w i d e s t _':3}
print(get_stats(vocab))・実行結果
defaultdict(int,
{('l', 'o'): 7,
('o', 'w'): 7,
('w', '_'): 5,
('w', 'e'): 8,
('e', 'r'): 2,
('r', '_'): 2,
('n', 'e'): 6,
('e', 'w'): 6,
('e', 's'): 9,
('s', 't'): 9,
('t', '_'): 9,
('w', 'i'): 3,
('i', 'd'): 3,
('d', 'e'): 3})上記より、「e-s」、「s-t」、「t-_」の出現回数が$9$で最多であることが確認できる。プログラムでは次に下記のような処理を行う。
vocab = {'l o w _' : 5, 'l o w e r _' : 2, 'n e w e s t _':6,'w i d e s t _':3}
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(best)
print(vocab)・実行結果
('e', 's')
{'l o w _': 5, 'l o w e r _': 2, 'n e w es t _': 6, 'w i d es t _': 3}上記より、出現頻度が最多の組をbestに格納し、merge_vocab(best, vocab)を実行することで”e”と”s”の連結を行う流れが確認できる。この処理を10回繰り返すことで下記のような結果が得られる。
vocab = {'l o w _' : 5, 'l o w e r _' : 2, 'n e w e s t _':6,'w i d e s t _':3}
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(best)
print("===")
print(vocab)・実行結果
('e', 's')
('es', 't')
('est', '_')
('l', 'o')
('lo', 'w')
('n', 'e')
('ne', 'w')
('new', 'est_')
('low', '_')
('w', 'i')
===
{'low_': 5, 'low e r _': 2, 'newest_': 6, 'wi d est_': 3}また、下記のようにプログラムを改変すると10回繰り返した際の辞書を得ることができる。
vocab = {'l o w _' : 5, 'l o w e r _' : 2, 'n e w e s t _':6,'w i d e s t _':3}
num_merges = 10
bpe_dict = []
for i in range(num_merges):
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get)
bpe_dict.append("".join(best))
vocab = merge_vocab(best, vocab)
print(best)
print("===")
print(bpe_dict)・実行結果
('e', 's')
('es', 't')
('est', '_')
('l', 'o')
('lo', 'w')
('n', 'e')
('ne', 'w')
('new', 'est_')
('low', '_')
('w', 'i')
===
['es', 'est', 'est_', 'lo', 'low', 'ne', 'new', 'newest_', 'low_', 'wi']BPE(Byte Pair Encoding)では上記のように得られる辞書を元にsubwordにidを割り当て、以後の処理を行う。