
機械学習(machine leanring)の大別にあたって「教師あり学習(Supervised Learning)」、「教師なし学習(Unsupervised Learning)」、「強化学習(Reinforcement Learning)」の三つが挙げられることが多いですが、入門コンテンツの多くはミスリードになるような解説が多く、特に「教師なし学習」に関して論文などで調査を行う際などにわからなくなる場合があります。当記事ではその解決にあたって、それぞれの定義に関して詳しく確認を行います。
基本的な考え方
「教師あり学習(Supervised Learning)」、「教師なし学習(Unsupervised Learning)」、「強化学習(Reinforcement Learning)」の三つが機械学習の大別に挙げられることが多いですが、「教師なし学習」を「クラスタリング」などのアルゴリズムと対応させて解説を行うことでミスリードになりやすいので注意が必要です。このような解説がなされることで「教師あり/教師なし」に対応してそれぞれアルゴリズムがあると考えがちですが、この考え方は適切ではありません。
「教師あり/教師なし」に対応するのは「アルゴリズム・学習の仕組み」ではなく、「前処理も含んだ処理全体」です。たとえばDeep Learningを考えた際に、下記のようにそれぞれ「教師あり学習」、「教師なし学習」、「強化学習」の三つの考え方が対応します。
・教師あり学習
-> ImageNetの分類 etc
・教師なし学習
-> Auto Encoder、GAN、BERT etc
・強化学習
-> Deep Q-Network etc上記のようにDeep Learningを考えた際に「教師あり学習」、「教師なし学習」、「強化学習」の三パターンを考えられることから、「ニューラルネットワーク」のような「学習の仕組み」に基づいて三つの大別を行うことができません。
ここでDeepLearningなどを考える際によく出てくるのが「人間がアノテーションを与えるかどうか」という視点です。たとえばImageNetの分類では画像$X$に対し、正解ラベル$y$を人間が作成し学習を行いますが、Auto EncoderやGANは画像$X$があれば学習を行うことができます。
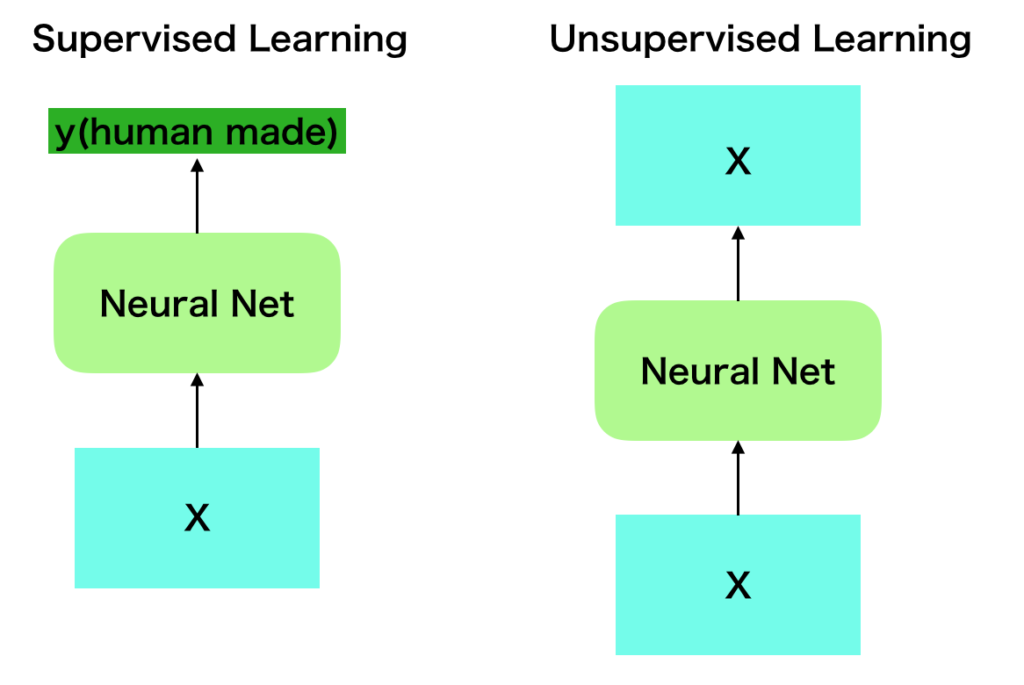
上図で「通常の教師あり学習」と「教師なし学習に対応するAuto Encoder」を元に具体的な図示を行いましたが、ニューラルネットワークの入力はどちらも$X$である一方で、出力は人間がラベル付けを行なった(human made)$y$と、入力と同様な$X$でそれぞれ異なります。
ここで着目すべきは手法自体はどちらもニューラルネットワークである一方で、出力にラベルを与えたかどうかで「教師あり/教師なし」を判断する場合も多いことです。したがって「ニューラルネットワーク」のような「学習のアルゴリズム」で判断するよりはfit(X,y)と書くかfit(X)と書くかのように関数のように理解する方が良いと思います。fit(X)と書く場合は「教師なし学習」と考える一方で、内部で教師に該当するyを生成しfit(X,y)を実行する場合もあり、この場合はfit(X)の視点で見れば「教師なし学習」、fit(X,y)の視点で見れば「教師あり学習」のように考えることができると思います。
次節で「教師なし学習」を詳しく確認するにあたってBERTの事前学習(pre-training)を取り扱いますが、BERTのMLM(Masked Language Modeling)を題材にすることで「教師なし学習」がより理解できると思います。
ここまで「教師あり/教師なし」に関して確認を行いましたが、「強化学習」も同様に「強化学習に対応するアルゴリズムがある」というよりは、$X$の代わりにエージェントと呼ばれるプレイヤーを定義して学習を行う場合を「強化学習」と呼ぶという理解の方が良いと思います。
強化学習に関しても詳しく確認すると難しくなるので、詳細は次節で確認を行います。
詳細
教師あり学習
教師なし学習
前節では$X$をニューラルネットワークの入力と出力に用いるAuto Encoderを元に「教師なし学習」を確認しましたが、当項ではBERTの事前学習(pre-training)を例に「教師を乱数を用いて”機械的に”作る」場合の確認を行います。
BERTの事前学習であるMLM(Masked Language Modeling)では文章に対応する系列を取り扱うDeepLearningの主流の手法であるTransformerに対し、一定確率でランダムに$X$にあたる入力を消去し、これを出力であてるというタスク設定を行います。
より具体的には$X = (x_1,x_2,x_3,x_4,…) = ($私, は, 本屋, に, 行った, 。, 教科書, を, 買った, 。$)$という文があった際に入力を$($私, は, MASK, に, 行った, 。, 教科書, を, 買った, 。$)$に変化させ、出力で「本屋」を予測するようなタスクをMLM(Masked Language Modeling)では取り扱うと理解すれば良いです。少々分かりにくいので図で表すと下記のように表すことができます。
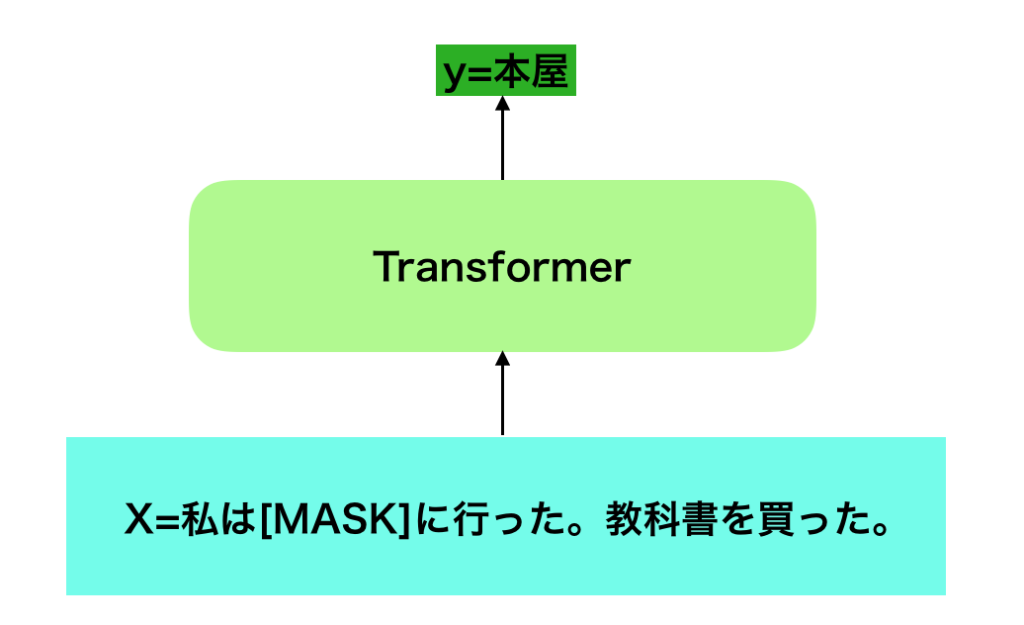
ここで上記で表したMasked Language Modelingは入力$X$に対して$y$を予測している問題のようにも見えるので「教師あり学習」であると考えがちですが、出力にあたる「本屋」は乱数などを用いて作成したものであり人手でアノテーションを行なったわけではありません。
このような例もあるなど、DeepLearningを考える際には「教師あり/教師なし」という用語は単に「アノテーションを作成するコスト」に着目することが多いです。この解釈にあたっては、「ニューラルネットワーク」単体で見れば常にfit(X,y)であるのに対して、BERTのように前処理まで含めばfit(X)であり教師なし学習という見方ができるとわかりやすいのではないかと思います。
強化学習
強化学習(Reinforcement Learning)に関しては直感的にわかりやすい定義が少ないですが、意思決定主体のエージェント(Agent)を定義し「エージェントの最適行動を考える問題」と理解すると良いと思います。
もう少し詳しく考えると「エージェントが何らかの状態(state)を観測した際に意思決定(action)を行いその結果新しい状態と報酬を観測する場合、一連の意思決定に基づく報酬を最大化する意思決定を考える問題」と考えると良いです。
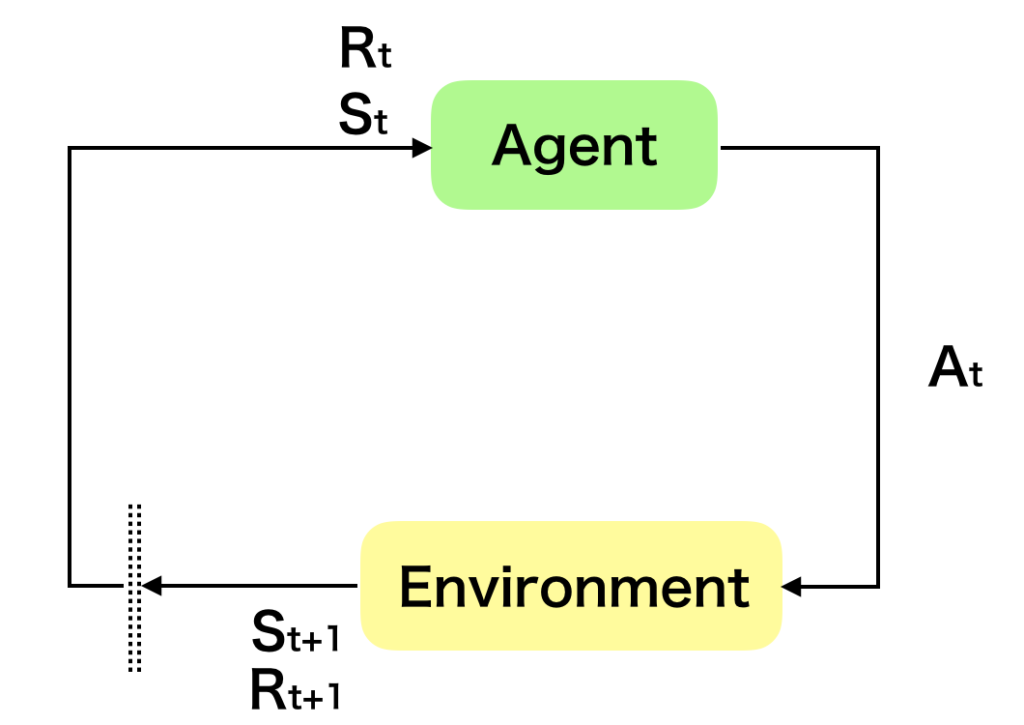
これに関連して上図のような図がよく用いられますが、この図を元に理解するにあたっては下記に注意すると良いです。
1) 強化学習は逐次的意思決定問題(Sequential Decision Making Problem)を取り扱う
-> 強化学習は系列処理の問題に意思決定の概念を導入し、意思決定によって発生する報酬を元に意思決定方針の最適化を考えると理解しやすいです。図の理解にあたっては1つの時点における意思決定に関連する報酬のみを表示しており、実際は逐次処理の一部であることには注意が必要です。
より具体的には「テレビゲームを行う際に、画面を見てコントローラーでコマンドを入力し、状況が遷移する際に報酬が発生すれば獲得する」を1フレームと見た際に、この1フレームの概略が図に対応すると考えれば良いと思います。
2) 大まかに理解する際は環境(Environment)ではなくエージェント(Agent)ありきで考えるべき
-> 「強化学習には環境とエージェントがある」という解説がされやすいですが、方針の最適化を行うのは環境ではなくエージェントであることは注意しておくと良いです。環境は迷路や囲碁などのようにはっきり定まる場合もあればAtariゲームのように何らかの定義が必要な場合もあります。
したがって、大まかに把握する際はエージェントが自身を取り巻く環境に対し何らかの意思決定を行い報酬などの反応を通して方針を学習すると考えると良いです。
3) DeepLearningなどを用いる際はエージェントの意思決定をDeepLearningを用いて近似する
-> 1)、2)で取り扱ったように強化学習ではエージェントの最適行動方針を学習します。この考えに基づいてDeepLearningを導入するにあたっては、エージェントの最適な意思決定をDeepLearningでいかに近似するかがメインの課題になると理解しておくと良いと思います。強化学習に関しては下記などで別途取りまとめを行なっているので下記も参考にしてみてください。
https://www.hello-statisticians.com/explain-terms-cat/reinforcement_learning1.html
また、下記のChapter$1$などに強化学習の定義に関してまとめられているので、専門的・学術的なリファレンスに用いる場合は下記を参照すると良いと思います。
その他
半教師あり学習(semi-supervised learning)
深層学習[第2版]の11.4節の内容を元に以下取りまとめます。半教師あり学習(semi-supervised learning)はラベル付きの訓練データ$\mathcal{D}_L$とラベルのない入力のみのデータ$\mathcal{D}_{UL}$がある際に両者を効果的に用いて目的タスクを学習する方法です。
半教師ありの手法に関しては、主に一致性正則化(consistency regularization)、擬似ラベル(pseudo label)、エントロピー最小化(entropy minimization)の$3$つの手法があるので以下それぞれに関して取りまとめを行います。
・一致性正則化(consistency regularization)
一致性正則化(consistency regularization)はラベルのないサンプルの$\mathbf{x}$を中身が変わらない範囲で$\mathbf{x} \to \mathbf{x}’$のように変動させるとき、予測結果が変わらないであろうことに基づく手法です。
関数$f$を元に出力の近似を行う際に出力の変化を測る尺度を$\delta(f(\mathbf{x}),f(\mathbf{x}’))$のようにおき、これに基づいて正則化項を構成し誤差関数に加えることで$\mathcal{D}_{UL}$に基づいて正則化を行うことができると考えることができます。
・擬似ラベル(pseudo label)
擬似ラベル(pseudo label)は先に$\mathcal{D}_L$を用いて教師ネットワーク$T$を学習させたのちに、$\mathcal{D}_{UL}$を教師ラベルを用いて分類し、生徒ネットワーク$S$を教師ネットワークの出力に基づいて学習させるという手法です。
・エントロピー最小化(entropy minimization)
エントロピー最小化(entropy minimization)はネットワークの出力結果の各クラスのスコアのエントロピー$\displaystyle – \sum_{k=1}^{K} f(\mathbf{x})_k \log{f(\mathbf{x})_k}$を最小にする手法です。予測結果の事後確率の分布が1つのクラスのみが大きくなるときエントロピーは小さくなるので、$\mathcal{D}_{UL}$の予測のエントロピーが小さくなるように学習させると考えると良いです。
まとめ
参考
・機械学習中級(筆者作成)
https://www.amazon.co.jp/gp/product/B08CRSY7XN/
・深層学習[第2版]